
Units of AI Governance
For scaling AI Governance and Risk Management

For the past few months I have been giving talks at the meeting point of two disciplines I know well. Model risk management, from my years supervising models at MAS. And computer science, from an ill-advised side quest to finish a PhD at 42.
The AI risk management guidelines I wrote for Singapore’s financial sector grew out of both, and they rest on three units of governance: the model, the system, and the use case. Lately something seems missing.
These three units - the model, the system, and the use case - are the ones we already know how to govern, but they share a weakness. Each is specific, tied to one particular application.
Above them sits a second set of three that we are beginning to think about for governance: the archetype, the capability, and the workflow. These seem to be better as they generalize.
Why is this important? A unit of governance is something you point a control at. Too granular and it may work, but not scale.
Let’s draw a line between 6 units. The units below the line are where governance lives today. The units above it may be worth considering for governing AI at scale.
The six of them, and the line between, look like this.
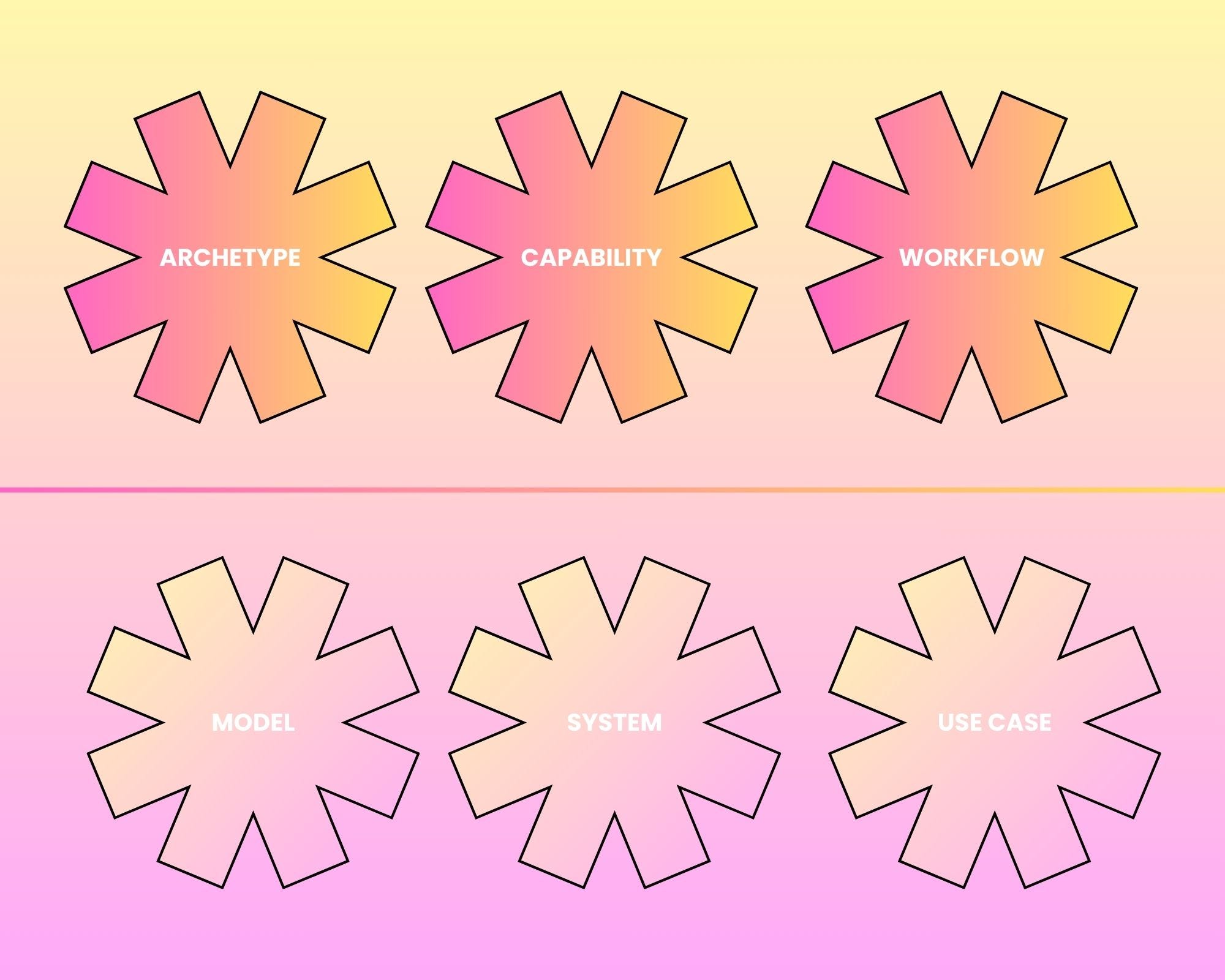
Below the line
The three units below the line are not new. We imported each of them from a discipline that already existed - model risk management, technology risk management, and the use-case registers that AI governance frameworks already lean on. That is their strength and their limit. The methods are mature. But they were built for a world where each thing you governed was specific and countable.
The model
I’ll start where I always do, with the model. It is my favourite, and it is the one thing that makes an AI system different from any other piece of software. The first models I met were simple curves - bootstrapping zero rates off swap quotes in a financial engineering classroom, then their more sophisticated cousins, Black-Scholes, SABR, Hull-White, Heston.
For years a single supervisory letter, SR 11-7, was the only guidance that governed any of it. I took a Masters in Financial Engineering but was not a great student, and so I stayed confused about those models in finance for a long time.
What finally made them click was meeting their successors - decision trees, random forests, gradient boosted trees, then the deep learning models, the RNNs and CNNs, and eventually LLMs. They are all more general versions of the same idea. Even an agent is just a system wrapped around an LLM.
Once you can see the parts every model shares - the function you choose, the objective, the optimization method, the way you evaluate it - the questions you need to ask barely change from one to the next. They all come back to those parts, and to the assumptions beneath them.
But something did change on the way from the curve to the LLM, and it matters for governance. A Black-Scholes model is written down. You can read its assumptions off the page and argue with them. A learned model is not written down in that sense - its behaviour lives in weights shaped by data, not in an equation you can inspect. So validation has to change. It stops being a check of the maths and becomes a probe of the behaviour. You can no longer read the model; you can only interrogate it.
That is the real break, and it is why so much traditional model risk practice feels half-applicable to AI. The questions survive. How you answer them does not. And we see this in Agentic AI increasingly due to their ability to take actions and not just generate outputs.
But that shared structure is also where we see commonalities in risks. I think of them as three U’s.
Uncertainty - the irreducible randomness you can never remove, and the reducible gaps you can close with more data. Every model has both. The work is knowing which is which, because you waste effort trying to engineer away the part that won’t move.
Unexpectedness - the way more complex models behave in ways nobody designed, in emergent capabilities, adversarial weaknesses, and misalignment. The more general the model, the more of its behaviour was never specified by anyone, which means more of it is found rather than built.
Unexplainability - the varying degree to which we can actually say why a model decided what it did. Transparency, explainability, interpretability are all really one question asked at different depths: can we understand this enough to stand behind it? Understand. Not quote some figures generated by an explainability method you don’t understand.

Governing the model, then, is mostly documentation, independent validation, and benchmarking - the same spine as classical model risk. The trap is treating the benchmark as the answer. A model can top every public benchmark and still fail in your context, on your data, against your adversaries, because the benchmark measured a general skill and you are deploying a specific one. The benchmark tells you the model is capable. It does not tell you it is safe here.
It is telling that when the Fed, the OCC and the FDIC replaced SR 11-7 this April with SR 26-2, after fifteen years, they carved generative and agentic models out of scope as too novel and fast-moving. I understand the caution. But the effect is that the fastest-moving, least-understood models are the ones left with the least guidance. Given how tightly the quantitative and the modern connect, that exclusion still puzzles me.
The system
A model, though, never runs on its own. Wrap code, tools and memory around it and you have a system - and for most of my career the system was someone else’s problem. I came up in model risk: development documentation, validation reports, stress tests. Technology risk lived down the corridor, a different team with different acronyms, and I treated it as none of my business. AI changed that.
To see why, it helps to name what a system actually is. Around the model sits the prompt scaffolding that frames every request, the tools it is allowed to call, the memory it carries between turns, the retrieval that decides what context it sees, and the guardrails bolted on at the edges. Every one of those is a knob. Turn any of them and the same model produces different behaviour. The same prompt, through two different stacks, lands in two different embedding spaces and comes back with two different answers. So a model card tells you very little on its own. Two deployments of the same weights are two different risk objects, and the thing you actually have to govern is the configuration, not the checkpoint. We call them fancy names like harness or loop engineering these days for Agentic AI. But it’s really just a system with slightly more dynamism and autonomy.
This is where most so-called AI incidents really live. The system around the model is increasingly where the performance, the variance, and most of the failure modes actually live, and it cuts both ways. On the upside, changing nothing but the harness around a model can lift its score on the same benchmark dramatically, sometimes close to double - the model didn’t get smarter, the system around it got better at using it. On the downside, the system is where the incidents are landing - remote code execution in the Model Context Protocol, supply-chain compromises spreading through AI tooling, an over-permissioned tool, an unsanitized input, a secret written to a log. In almost none of them did the model fail. The thing around it did. We spent a great deal of worry on model monoculture. The system deserves more of that attention.
The use case
If the model and the system are how AI gets built, the use case is what it gets built for - and it is the layer almost every governance framework reaches for first. It is also the question I am always asked: what are the use cases? I find it frustrating because no one wants to understand the underlying mechanics and connect it to their tasks, but just want an AI use case served on a platter.
The pull is easy to understand. The use case is the unit the business names, the unit that goes into a register, the unit a board can hold in its head. It is the unit of value. So it becomes the unit of the inventory, and the inventory becomes the comfortable thing we can look at and boast about - “We have 1000 AI use cases!”
That comfort is the problem. A register of use cases gives you the feeling of coverage while the real risk objects sit a layer down, uncounted. It is the unit I trust least, for three reasons.
Not deep enough. A single fraud detection use case can hide transaction monitoring, an anomaly model, a generative assistant and a retrieval system underneath, each with its own failure modes. The use case enters the inventory once. Ten real things go ungoverned.
Not specific enough. Two banks can list the same wealth-advisory use case and mean completely different workflows, models, and risks. The label matches. Nothing beneath it does. So a control written against the label protects neither of them well.
Not scalable enough. Twenty use cases you can govern one by one. At two hundred the patterns underneath them simply repeat - retrieval, extraction, summarization, classification, recommendation, anomaly detection - and governing at the use-case level means redoing the same work every time you meet the same pattern wearing a new name.
The use case is the right unit to decide whether to build. It is the wrong unit to decide how to control. The unit that actually scales is one layer further down, or one layer up.
Above the line
Everything below the line is specific by nature, which is why the work never compounds - each new system is a fresh job. The units above the line are different in kind. They are patterns, not instances. Govern a pattern once and every instance that fits it inherits the work. That is the whole reason to climb.
The archetype
Go up a layer and you reach the archetype - the first unit that scales. I saw it during the generative-AI wave, before agents arrived: an LLM is general-purpose, but people kept getting more out of it by putting it in a box. Retrieval-augmented generation. Summarization. Classification. Information extraction. Code generation. Chat.
A general-purpose tool is almost ungovernable precisely because it can do anything - there is no fixed set of risks to reason about. The archetype trades a little of that generality for something you can actually hold: a known shape, with known failure modes.
Naming the box helps twice over. For building, it brings the recipe with it - the reference architecture, the prompt patterns, the libraries and settings that already work - so a new project starts from a known shape instead of a blank page. For governance, it brings the risk package with it - the failure modes that apply, the evaluation and testing metrics that matter, the controls you need - none of it worked out fresh each time. This is the clearest answer to the worry that risk management blocks innovation: done at the right unit, it is exactly what lets you reuse.
Governance stops being per-project checklist bureaucracy and becomes a library. You write the controls for retrieval once, and every retrieval system in the firm draws from them.
The same idea shows up across the common archetypes:
Summarization - the dominant risk is the model inventing detail that was never in the source, so faithfulness is the metric you cannot skip, and high-stakes summaries earn a human check.
Code generation - the risk shifts to security, so the check is correctness plus a vulnerability scan, with the small mercy that bad code tends to fail loudly rather than silently.
Retrieval - the risk lives in what gets retrieved, wrong chunks or leaked embeddings, so you test whether the right context was pulled, whether the answer is grounded in it, and you watch the vector store closely.
Three archetypes, three different shapes of risk, but within each one the work is done once and inherited by every use case that adopts it. Constraints, it turns out, are what make a thing governable at all.
The capability
Archetypes tamed generative AI. Agents need the same move, one level harder, and it comes down to two questions: what can the agent do, and how far can it go on its own?
The first question is capability. In my mind, a capability is not what the underlying model can do, or how it scores on a benchmark; it is what an agent can actually do in the world, on real tasks - a repeatable building block with three things attached to it. The actions it covers. The authority it is granted to take them. And the evidence it must produce that it did so within bounds. Retrieve a customer’s transaction history is a capability. Move money between accounts is another, with far more authority and a far higher bar of evidence.
Defined this way, an agent stops being a mysterious opaque whole and becomes a set of capabilities you can reason about one at a time - decompose the agent into the capabilities it exercises, and compose your oversight back up from there.
This is why the benchmark misleads. A model topping a coding benchmark tells you nothing about whether an agent built on it should be allowed to merge to the main branch unattended. The benchmark measures skill in the abstract. Capability is about authority in the world. The two come apart, and governance lives in the gap.
Two pieces of work from very different directions arrive at the same place: GovTech’s Agentic Risk and Capability framework (https://arxiv.org/abs/2512.22211), by Shaun Khoo, Roy Ka-Wei Lee and Jessica Foo, and the work on runtime governance in finance (https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6567199) that Łukasz Szpruch, Agus Sudjianto, Tanveer Bhatti and I did. Both land on capability as the better unit for governing agents.
And it scales the way the archetype does, but with guards baked in. Four agentic systems at a wealth firm - a service bot, a trade drafter, a compliance checker, a KYC assembler - look like four separate jobs, but they lean on the same handful of capabilities: document retrieval, fact extraction, policy checking. Govern those once - the authority each is granted, the evidence each must leave behind - and the rest is configuration, not construction. The fifth, sixth, seventh and even the hundredth systems cost almost nothing to govern, because they are new arrangements of capabilities you have already controlled.
The workflow
The second question - how far an agent can go - is the workflow. The workflow is what you allow it to do, designed up front: the branches, the approval gates, the points where it must stop and ask, or abstain. The trajectory is what it actually did, visible only afterwards. Most of the time the two match. The risk lives in the times they don’t, and runtime governance is the layer that watches the live trajectory against the allowed workflow and acts when they diverge - pausing for approval, refusing an action, stopping a run before it compounds.
Singapore’s Model AI Governance Framework for agentic AI (https://www.imda.gov.sg/-/media/imda/files/about/emerging-tech-and-research/artificial-intelligence/mgf-for-agentic-ai.pdf) frames the same thing as action space and autonomy - what the agent is allowed to touch, and how far it goes alone. They are two dials. Widen the action space and the agent can reach more of the world. Loosen the autonomy and it asks permission less often. Turn both up and the set of possible trajectories explodes, far faster than anyone’s intuition tracks. That is how almost every agentic incident happens: the workflow quietly permitted an action it shouldn’t have, the autonomy let the agent take it without asking, and nothing was watching while it ran.
The simplest test I know is whether someone can draw your agent’s workflow on a whiteboard - the branches, the gates, the places it must stop. If they can’t, then no one has actually drawn its limits, which means the limits don’t exist yet. And the trajectories, when they arrive, will not be the pleasant kind of surprise.
The whole picture
So there are six units, not three. Three below the line - model, system, use case - the established disciplines, and the specific. Three above it - archetype, capability, workflow - the ones we are still working out, and the ones that scale. The move up the line is a move from governing things to governing patterns, and it is the only version of AI governance I can see that keeps pace as the number of systems climbs.
I am still thinking this through. The line may move, and new units may yet appear above it.
But the question worth thinking about is a ridiculously simple one. Of the six, which is your AI actually governed at - and is it the one that can keep up as the number of AI systems grows? And it will.
This began as a series of short notes, written over a few weeks while I worked the idea out in public. Here it is in one piece.