
Thinking in AI: Part I
Starting a new series

I started a PhD in AI at 42 with zero computer science background - a few months earlier I had a full time job managing the investment risk of Singapore’s foreign reserves. Surrounded by 25-year-olds who actually knew what NP hard meant.
I knew nothing about this world.
I still remember my PhD supervisor’s reaction when I showed him yet another shiny concept from the latest paper. Unimpressed, he said: “Let’s start with the task.” I didn’t appreciate it then. Three years of fiddling with data types and tasks - networks, time series, multimodal data; regression, classification, forecasting - made me see the point.
That’s what this series is about. Something quite simple. Perhaps too simple. But I thought worth writing down.
How to see AI through the lens of data types and tasks. I call it “Thinking in AI”.
Nothing fancy.
But why does it matter then? In this age of LLMs and Agentic AI? Why not just jump ahead to prompt engineering, context engineering, or what one calls harnesses these days?
Because prompts are brittle. Context just means what goes into the Large Language Model. LLMs are not the only type of model in AI. And a framework for thinking is more durable than a harness.
AI has always been about classification, regression, generation, ranking, forecasting and many more tasks.
LLMs wrap over those tasks, in a more generalized manner (hence the name foundation models). Agents are another - an LLM orchestrating tools and other LLMs on tasks.
Strip the headline away and the data types and tasks are still the ones that were there ten years ago.
It all comes down to a few frameworks - for data, tasks, and methods - and how they compose into what we now call generative AI and agents.
So if you’re here for the frontier, you are in the wrong place. This series is deliberately about the boring fundamentals.
If you already know the fundamentals of the journey from machine and deep learning to LLMs and Agentic AI, then this might also be too simple for you.
For everyone else, I hope this is helpful in some way/
Start with the task
I call it “Prompt and Pray.”
You’ve probably sat through one of these. A workshop, a webinar, a demo. Someone shows a clever prompt. Everyone marvels at the output. Another prompt. Another marvel. A chuckle when the model gets something wrong. A tweak, and we’re back to marveling.
No one stops to ask what the model is actually doing. What data it’s seeing. What task it thinks it’s solving. Why it works on this example but might not on the next.
That frustrates me. Not because prompting isn’t useful. Because it skips every step that lets you understand the result.
So I wrote this. A short series on the part of AI that doesn’t expire when the next model drops.
Boring fundamentals, I promised. Here’s the most boring one. Before reaching for a model, write down what you’re actually trying to do.
Three questions.
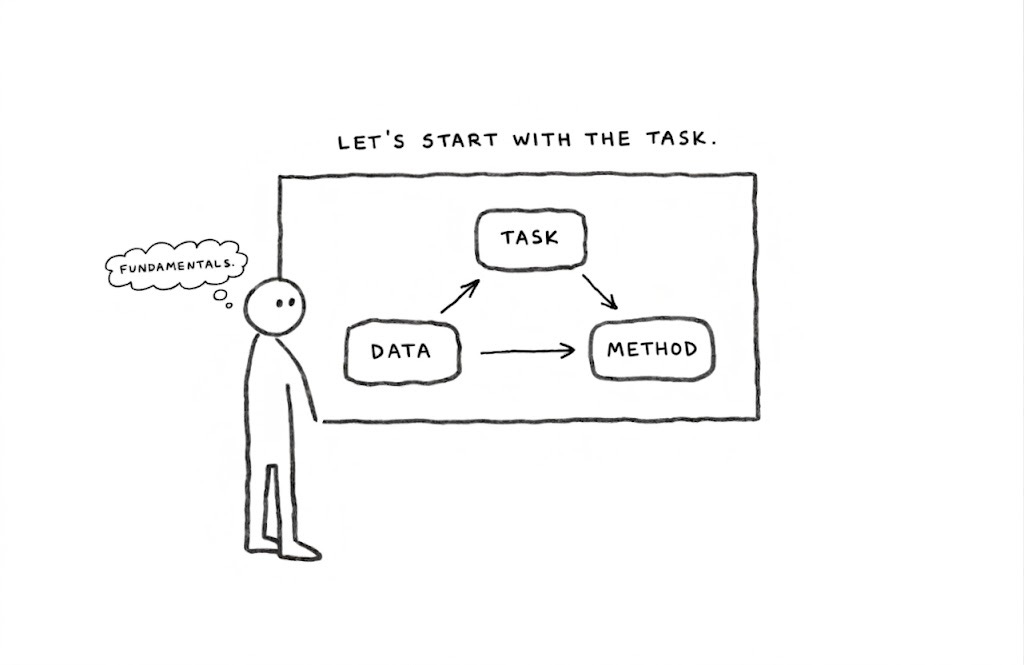
What data do I have?
What task am I doing?
Which method fits?
Most AI problems start with those three. Not how to use the latest shiny new AI model.
Same problem, different roles
The use cases below look different. But are they really?

Different contexts. The same underlying job: turn a flood of messy inputs into one decision.
Take the portfolio analyst.
From data to tasks
Two tempting responses to all this.
Throw it all at an LLM and shrug when it hallucinates.
Build a bespoke solution from scratch.
The useful next question is “which tasks am I doing?” Once the tasks are clear, the method question gets much smaller. The method might not even be AI.

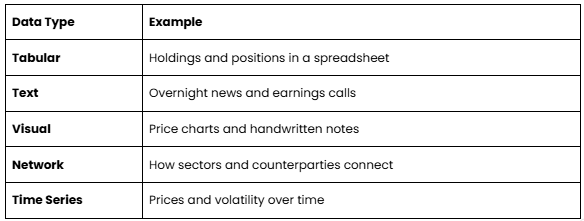
We can usually map use cases and problems to specific tasks. Some examples.
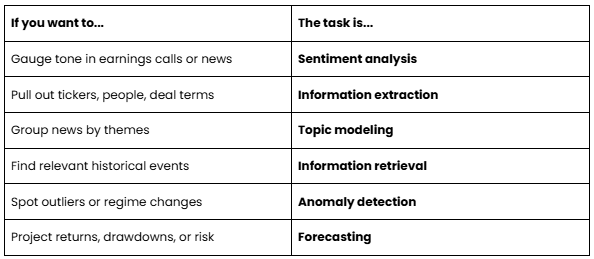
Each does a single, clear job. Sentiment reads tone. Extraction pulls out the tickers and names. Retrieval finds the past episodes that are similar. Forecasting projects the future.
A use case or solution to a problem usually chains some of these together.
Even LLMs and Agentic AI work this way. A general LLM seems to break the frame - one model, any task. But the task didn’t disappear; it moved into the prompt. Ask for a summary and it summarises. Ask for sentiment and it classifies. Change the prompt and the context, and you’ve changed the task. An agent just chains those prompts - planning, retrieval, reasoning, generation. Each step has its own data type, its own task, its own method. Decomposition is how agents work under the hood.
The same move works beyond the analyst. The journalist chasing a story, the clinician reaching a diagnosis, the lawyer finding the case that matters - each breaks down into the same handful of tasks. Different roles. Same approach.
Where this goes next
The rest of the series dives deeper.
Part I - Components. The math behind any AI model. The data types it sees. The tasks it does.
Part II - Setups. How those components compose into machine learning, deep learning, generative AI, and agentic AI. Different names, same parts.
Part III - Data Types. Five worked examples of the framework. Tabular, text, image, networks, time series.
Tabular. Why a small machine learning model on a 40-year-old spreadsheet can still beat billion-parameter models at most real decisions.
Text. How a five-step language pipeline collapsed into a single model.
Images. How an invisible change to a handful of pixels turns a stop sign into a speed-limit sign.
Networks. What AlphaFold and your org chart have in common.
Time series. Why your ECG and a stock chart are the same kind of problem.