
Simple Reading List on Explainability & Interpretability
“But we need to ensure we have explainability!”

“But we need to ensure we have explainability!”
I hear this in meetings constantly. Someone senior gestures vaguely, everyone nods, and the conversation moves on.
My thought is always: What does that actually mean?
Inherently interpretable models? Post-hoc SHAP values? Explanations for customers, users, risk managers, senior management?
At what level? Individual predictions or overall model behavior?
Here is a simple reading list that could perhaps help understand the differences. There are probably hundreds (or even thousands) of relevant works, but I just picked a representative few from my library for the following phases, from when models were simple to explain, to the impossible task with today’s trillion-parameter AI.
Note: I have used open-access links from arXiv as far as possible as some of the published versions are behind a paywall.
Phase 1: From Inherent Interpretability to Post-Hoc Explainability
1. “Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead” — Rudin (2019) | Nature Machine Intelligence
This 2019 paper argues against using post-hoc explanations for black-box models and the need for inherently interpretable models. This is a highly cited paper that seems both quaint and prescient at the same time. arXiv:1811.10154
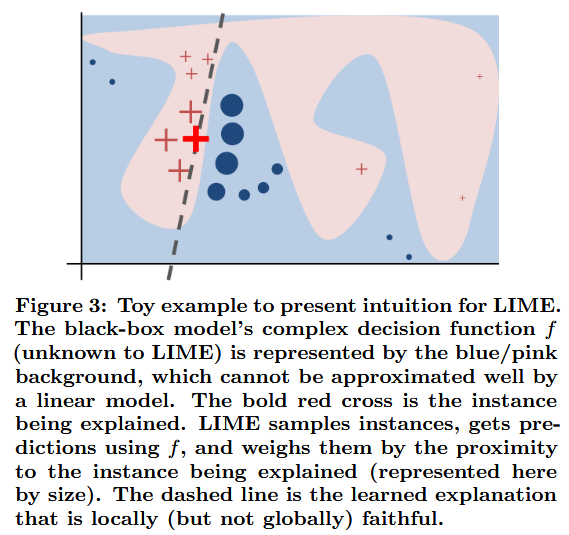
2. “Why Should I Trust You?: Explaining the Predictions of Any Classifier (LIME)” — Ribeiro, Singh & Guestrin (2016) | ACM SIGKDD 2016
THE paper that proposed LIME, based on learning a local interpretable surrogate model around each prediction. The paper goes beyond local explanations and also shows how to select a diverse, representative set of explanations to explain the model. arXiv:1602.04938
3. “A Unified Approach to Interpreting Model Predictions (SHAP)” — Lundberg & Lee (2017) | NeurIPS 2017
THE paper that proposed SHAP for post-hoc explanations, and proved that key existing methods then could be viewed as approximations of SHAP. Highlights 3 desirable properties - local accuracy (where the explanation model must match the output of the original model for the specific input being explained); missingness (where a feature must have no impact if it is set to 0); consistency (if a feature helps the model more, the explanation method will never penalize it with a lower score). NeurIPS 2017
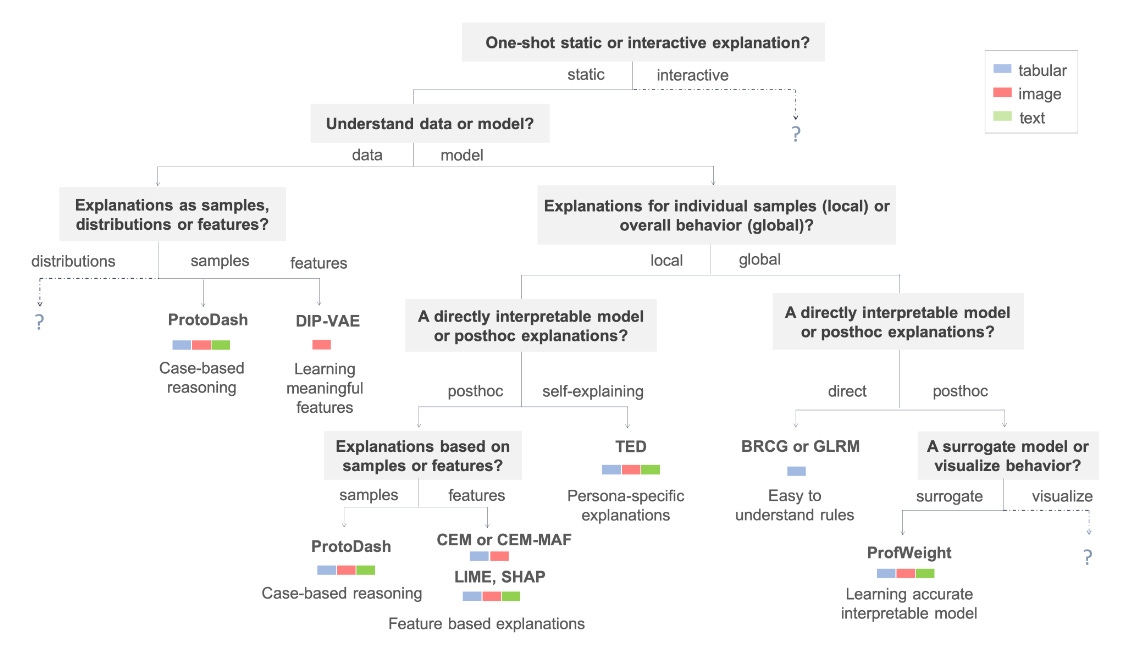
4. “AI Explainability 360: An Extensible Toolkit for Understanding Data and Machine Learning Models” | “One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques” — Arya et al., IBM Research (2019 | 2020) | arXiv preprint | Journal of Machine Learning Research
Goes beyond SHAP & LIME to other methods. Interesting as it highlights the need for persona-based explainability (to cater to different needs of say affected users vs. decision makers). Also classifies methods based on static vs. interactive, data vs. model understanding, local vs. global, directly interpretable vs. post-hoc. arXiv:1909.03012 | JMLR paper
5. “Interpretable Machine Learning” (Book) — Molnar (2022) | Open-access textbook
An open-access textbook covering the full spectrum, from linear regression and decision trees to SHAP and counterfactuals. A must-read for anyone who wants to get a good handle on interpretability and explainability. christophm.github.io
6. “A Comprehensive Guide to Explainable AI: From Classical Models to LLMs” — Hsieh et al. (2024) | arXiv preprint
A textbook-style guide spanning the entire XAI spectrum—from intrinsically interpretable models (decision trees, linear regression) through post-hoc methods (SHAP, LIM) to LLM-specific techniques. Another good read. arXiv:2412.00800
Phase 2: Taking A Step Back to Critically Examine Explainability
1. “From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review on Evaluating Explainable AI” — Nauta et al. (2023) | ACM Computing Surveys
Proposes 12 properties in 3 dimensions for evaluating explanations - 1) What is explained? Correctness, Completeness, Consistency, Continuity, Contrastivity, Semantics; 2) How is it explained? Compactness, Composition, Confidence; 3) Who is it for? Context, Coherence, Controllability. arXiv:2201.08164

2. “How can I choose an explainer? An Application-grounded Evaluation of Post-hoc Explanations” — Jesus et al. (2021) | ACM FAccT 2021
Going beyond academic explanations and measures. Conducted a real world study where users had access to data only, data and model scores only, or data, model scores and explanations. It reveals a counterintuitive insight - adding model explanations makes human decision-making faster but can result in lower accuracy compared to reviewing raw data alone. arXiv:2101.08758
3. “Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods” — Slack et al. (2020) | AAAI/ACM AIES 2020
Another paper that reminds us to not overly trust explanation methods like LIME and SHAP. Paper shows that they can be easily fooled by adversarial models that hide their bias by distinguishing between real input data and the synthetic data (perturbations) used to generate explanations. arXiv:1911.02508
Phase 3: The Next Step (LLMs & Agents)
LLM Explainability
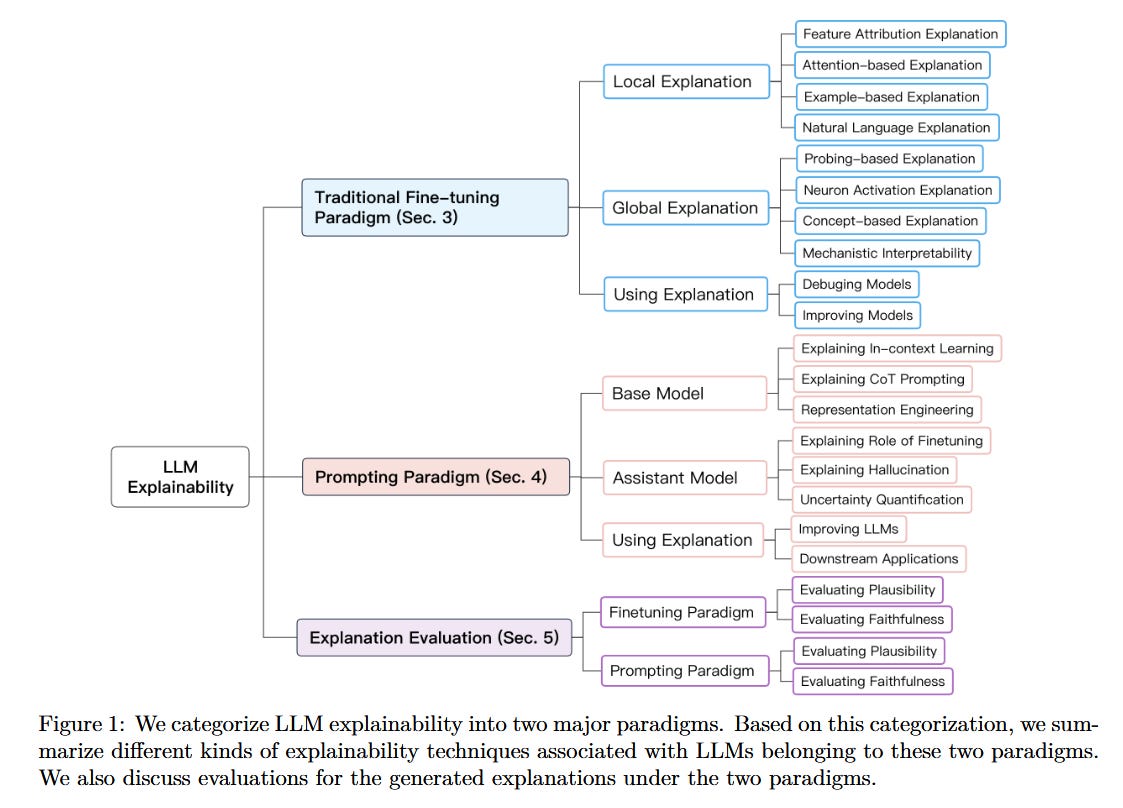
1. “Explainability for Large Language Models: A Survey” — Zhao et al. (2024) | ACM Transactions on Intelligent Systems and Technology (TIST)
Start here if you’re new to LLM explainability. Provides a good overview of techniques based on fine tuning (or training) paradigm (ranging from local to global methods); prompting paradigm (e.g., explaining chain of thoughts, using representations); as well as evaluating explanations for faithfulness and plausibility. arXiv:2309.01029
2. “XAI meets LLMs: A Survey of the Relation between Explainable AI and Large Language Models” — Cambria et al. (2024) | arXiv preprint
Maps the bidirectional relationship: how XAI improves LLMs, and how LLMs can generate explanations. Advocates for balancing interpretability with performance. arXiv:2407.15248
3. “Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey” — Dang et al. (2024) | arXiv preprint
Comprehensive survey on MLLM interpretability. Proposes framework across Data, Model, and Training/Inference perspectives. (Worth a read as vision-language models proliferate.) arXiv:2412.02104
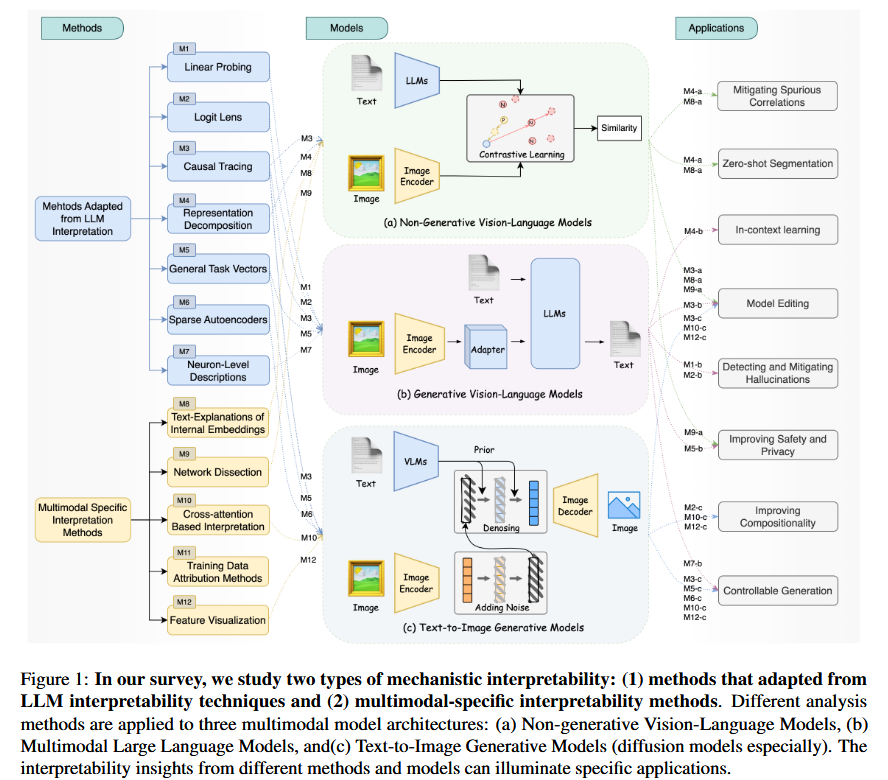
4. “A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models” — Lin et al. (2025) | arXiv preprint
Systematic comparison of how LLM interpretability methods adapt to multimodal settings. Identifies gaps between unimodal and crossmodal understanding. arXiv:2502.17516
LLM Explorability (Mechanistic Interpretability)
1. “A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models” — Shu et al. (2025) | EMNLP 2025
Comprehensive survey on SAEs, one of the hottest tool in LLM interpretability. Covers architecture, training strategies, feature explanation methods, and evaluation metrics. (If you want to understand what Anthropic is doing, read this.) arXiv:2503.05613
2. “Mapping the Mind of a Large Language Model” — Anthropic (2024) | Anthropic Research
Not a survey, but the landmark paper showing SAEs at scale on Claude. Circuit tracing, attribution graphs, and the famous “Golden Gate Bridge” feature. (This is where “understanding” LLMs actually starts.) anthropic.com/research/mapping-mind-language-model
3. “Persona Vectors: Monitoring and Controlling Character Traits in Language Models” — Anthropic (2025) | Anthropic Research
Shows how to identify and manipulate specific behavioral features (like sycophancy or honesty) using sparse autoencoders. Demonstrates practical applications of mechanistic interpretability for AI safety. anthropic.com/research/persona-vectors
Agent Explainability
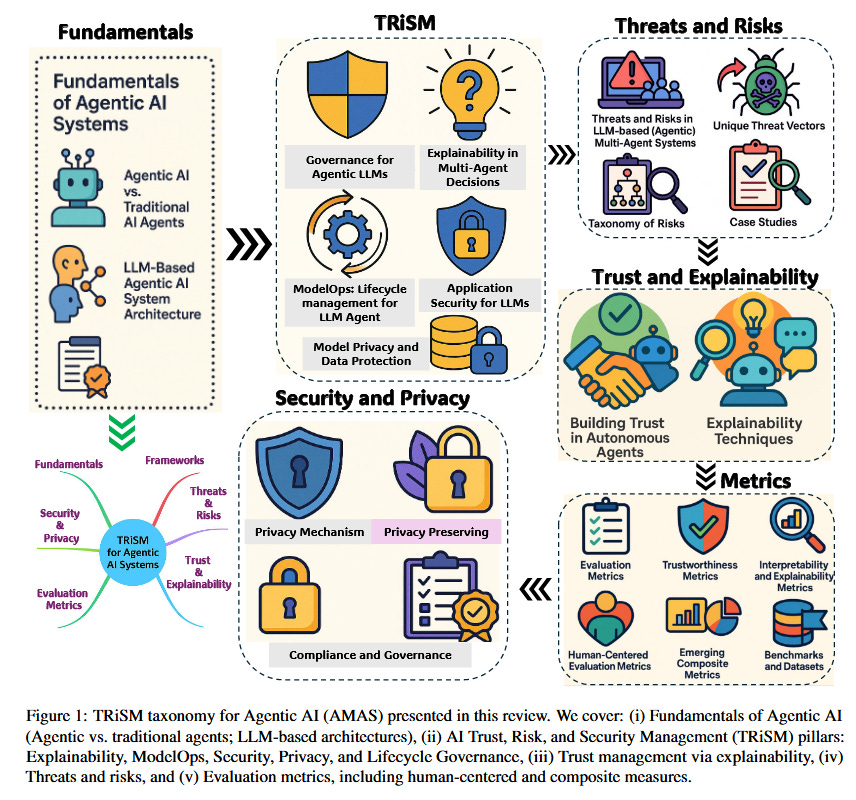
1. “TRiSM for Agentic AI: Trust, Risk, and Security Management in LLM-based Agentic Multi-Agent Systems” — Raza et al. (2025) | arXiv preprint
Adapts Trust, Risk, and Security Management framework for agentic AI. Includes explainability as key pillar alongside security and privacy. Proposes novel metrics for agent collaboration quality. arXiv:2506.04133
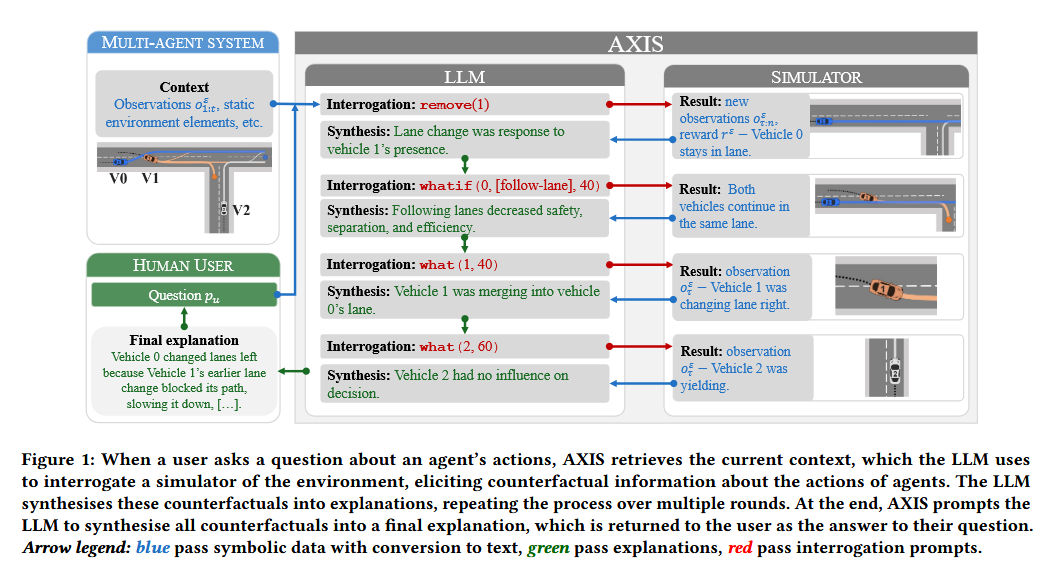
2. “Integrating Counterfactual Simulations with Language Models for Explaining Multi-Agent Behaviour” — Gyevnár et al. (2025) | arXiv preprint
The AXIS framework: LLMs interrogating simulators with “what-if” prompts to explain agent behavior. Shows 23% improvement in goal prediction accuracy. arXiv:2505.17801
Standards & Resources
1. NIST AI Risk Management Framework (AI RMF) - Explainability & Transparency
2. EU AI Act - Article 13: Transparency Obligation
artificialintelligenceact.eu/article/13
3. Resources -
This GitHub repository is your gateway to the full explainability landscape.
github.com/jphall663/awesome-machine-learning-interpretability
There are quite a few explainability/interpretability libraries around (see the repo above), but Agus Sudjianto’s is a good place to start. The documentation is a good read - https://modeva.ai/_build/html/index.html
—
“Can you explain why the model did that?”
It really depends on what you mean by “explain.”
Any must-reads in this area that you would recommend?
Fantastic curation. The progression from SHAP/LIME to SAEs and mechanistic interpretability maps exactly how the field shifted from "explain this prediction" to "understand this circuit." That Anthropic Golden Gate Bridge feature paper is a watershed moment, its like going from trying to explain individual neurons to actually reading the feature manifold. One gap I see though is production deployment scenarios where you need realtime explainability at scale, most of these methods dont address the latency vs fidelity tradeoff when explaining millions of inferences daily.