
Simple Reading List on Evaluation and Testing
From accuracy to ... the unknown edge

Housekeeping my Zotero library, I realized how much the evaluation landscape has shifted. Evaluating AI used to be straightforward: pick baselines and state-of-the-art models, choose metrics, run tests on unseen data. Highest score wins. That’s no longer the case.
Here is a simple set of papers and articles that could perhaps help understand these shifts. There are probably hundreds (or even thousands) of relevant works, but I just picked a representative few from my Zotero library for the following phases.
Phase 1: The Foundations (When Life Was Simpler)
Phase 2: Shifting of the Boundary (How LLMs made things harder)
Phase 3: The Reality (When the Rubber Meets the Road)
Phase 4: The Experimental (Evaluating AI Agents & AI as a Judge)
Note: I have provided open-access links from Arxiv as far as possible as some of the published versions are behind a paywall.
Phase 1: The Foundations (When Life Was Simpler)
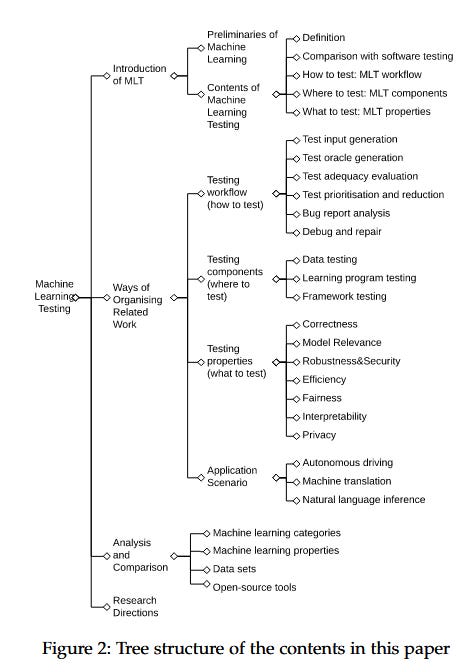
1. “Machine Learning Testing: Survey, Landscapes and Horizons” — Zhang et al. (2020) | IEEE Transactions on Software Engineering
A comprehensive map of the territory before Generative AI made things a lot more complex. It breaks testing down into properties (correctness, robustness, fairness), components (data, learning program, framework) and workflows. I like their categorization of functional properties (correctness, model relevance) and non-functional properties (robustness, fairness, privacy, interpretability, efficiency). Even back then, it highlighted that testing techniques for unsupervised, transfer and reinforcement learning needed more work (https://arxiv.org/pdf/1906.10742v2)
2. “Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning” — Raschka (2018) | arXiv preprint
The classic. A must-read by Sebastian Raschka, with many interesting takes: why simple accuracy metrics lie, the necessity of confidence intervals. Separates out performance estimation, model selection (same model, different hyperparameters), and algorithm selection (different ML algorithms). Goes into detail on bias, variance, different sampling techniques for model evals, as well as statistical tests for robust comparisons. (https://arxiv.org/pdf/1811.12808v3)
Phase 2: Shifting of the Boundary (How LLMs made things harder)
1. “A Survey on Evaluation of Large Language Models” — Chang et al. (2024) | ACM Transactions on Intelligent Systems and Technology (TIST)
Comprehensive survey covering LLM evaluation across multiple domains and tasks - what to evaluate, where to evaluate, and how to evaluate. The models covered may seem dated, but the concepts are still relevant. Covers tasks such as natural language understanding & generation, reasoning, robustness, bias and toxicity, trustworthiness. Outlines general vs. specific benchmarks; and automatic, human and crowd-sourced evaluations. Highlights gaps in bias, reasoning, memory, dynamic and robustness (which are still relevant today). Covers opportunities for AGI benchmarks, behavioral, robustness, dynamic, trustworthiness evals. (https://arxiv.org/pdf/2307.03109v9)
2. “On Robustness and Reliability of Benchmark-Based Evaluation of LLMs” — Lunardi et al. (2025) | arXiv preprint
A reminder that real-world applications involve significantly more variability than what standardized benchmarks can capture, and to be skeptical about the reliability of benchmark-based evaluations. Simple paraphrasing alone can easily lead to lower consistency, greater confusion. Data contamination makes benchmarks less reliable. Highlights the (semantic) brittleness of LLMs and the need to go beyond static benchmarks. (https://arxiv.org/pdf/2509.04013v1)
Phase 3: The Reality (When the Rubber Meets the Road)
Academics optimize for benchmarks; practitioners optimize for “doesn’t get us sued.” These guides bridge that gap.
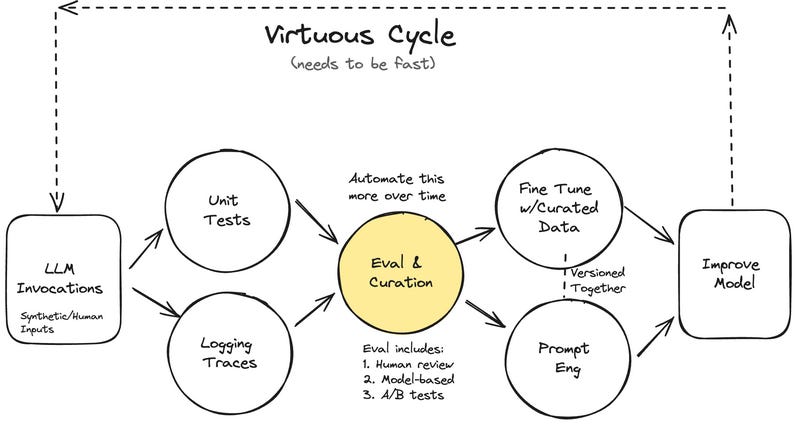
1. “Your AI Product Needs Evals” — Hamel Husain | Blog post (hamel.dev)
Read this if you want a guide on moving from “vibe checks” to systematic evaluation. Proposes a 3-level hierarchy: Unit Tests (scoping tests, assertions, creating test cases) -> Human/Model Evals (via logs, human reviews, automated evals) -> A/B Testing (to see how it works in real world). Highlights the invaluable role of evals in iterating quickly (which I full agree with), and curating good testing data (which could be used for fine-tuning later). Key takeaway - start simple, break things down. (https://hamel.dev/blog/posts/evals/)
2. “Task-Specific LLM Evals that Do & Don’t Work” — Eugene Yan | Blog post (eugeneyan.com)
A critique of generic metrics. Shows why BLEU/ROUGE are not as useful for reasoning and provides specific alternatives for a range of tasks. Going beyond accuracy, using probability based metrics, using models to compare source and generated text, using learned metrics, checking reproduction of training data to address copyright risks, classifiers for toxicity detection were some key takeaways. (https://eugeneyan.com/writing/evals/)
Phase 4: The Experimental (Evaluating AI Agents & AI as a Judge)
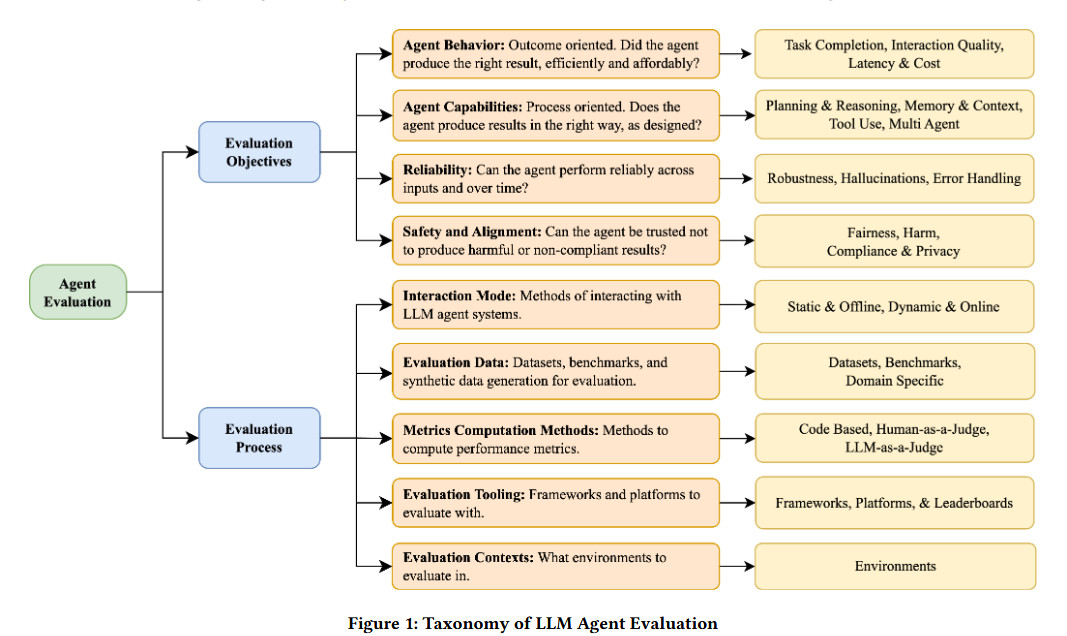
1. “Evaluation and Benchmarking of LLM Agents: A Survey” — Mohammadi et al. (2025) | ACM SIGKDD 2025
A taxonomy for agent evaluation, distinguishing between objectives (behavior, capabilities, safety) and process (static vs. dynamic). Covers the “What” (assessing agent behaviour, capabilities, reliability, safety & alignment), the “How” (static testing with datasets, dynamic testing with simulations, benchmarks, code-based, LLM as judge and human in loop evals). Also interesting in covering enterprise hurdles - role-based access controls, reliability guarantees, long horizon performance, policy compliance. The taxonomy presented in Figure 1 is excellent. (https://arxiv.org/pdf/2507.21504)
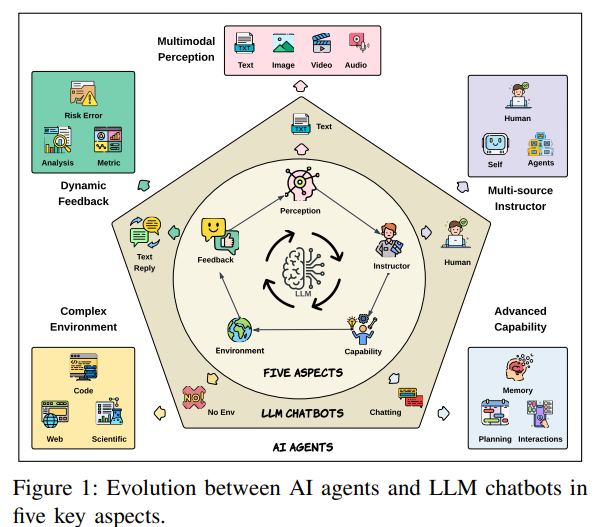
2. “Evolutionary Perspectives on the Evaluation of LLM-Based AI Agents: A Comprehensive Survey” — Zhu et al. (2025) | arXiv preprint
Frames evaluation as an evolutionary process. 5 key aspects when looking at this evolution - complexity of environments, number of sources of instructions, dynamism of feedback, degree of multimodal perception, state of capabilities. Also looks at this from the perspective of environments (coding, web, OS, mobile, scientific, gaming), and capabilities (planning, self-reflection, interaction, memory). (https://arxiv.org/pdf/2506.11102)
3. “LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods” — Li et al. (2024) | arXiv preprint
Interesting survey that with interesting points in the areas of Functionality, Methodology, Application, Meta-Evaluation, and Limitations. Covers the role of LLM judges in response & model evaluation, reward modelling, as verifiers, annotation and generation of synthetic data. Goes into the use of LLM judges in single and multi LLM systems, e.g., using prompt engineering to guide judge, finetuning judges in single LLM systems; or using cooperation, communication or aggregation of LLM judges in multi-LLM systems. Reminder that LLM judges have the same issues - bias, vulnerability to adversarial attacks, recency bias, hallucinations. (https://arxiv.org/pdf/2412.05579v2)
4. “Agent-as-a-Judge: Evaluate Agents with Agents” — Zhuge et al. (2024) | ICML 2025
Argues that static LLM judges fail for agents because they miss the intermediate steps. Proposes Agent-as-a-Judge framework that extends LLM judges with additional capabilities with components that ask, graph, locate, read, search, retrieve, memory, plan. Finds that it can outperform humans and LLMs as judges. (https://arxiv.org/pdf/2410.10934v2)
The Standards
1. NIST AI Measurement and Evaluation Projects | Government resource
A selection of NIST AI measurement and evaluation related projects. (https://www.nist.gov/programs-projects/ai-measurement-and-evaluation/nist-ai-measurement-and-evaluation-projects)
2. Singapore’s AI Verify Global AI Assurance Pilot | Government resource
A selection of case studies on organizations partnering AI testing specialists. (https://assurance.aiverifyfoundation.sg/)
3. ISO/IEC TR 29119-11:2020 (Testing AI Systems) | International standard
Part 11: Guidelines on the testing of AI-based systems. (https://www.iso.org/obp/ui/en/#iso:std:iso-iec:tr:29119:-11:ed-1:v1:en)
“How do you know it works?”
It’s no longer a simple question with a simple answer. More and more, we need a portfolio of tools and techniques for evaluation and testing.
Any must-reads in this area that you would recommend?
#AIRiskManagement #AIEvaluation #AITesting #AIReadingList