
Oxymorons in AI
Differentiating between foundation and embedding models

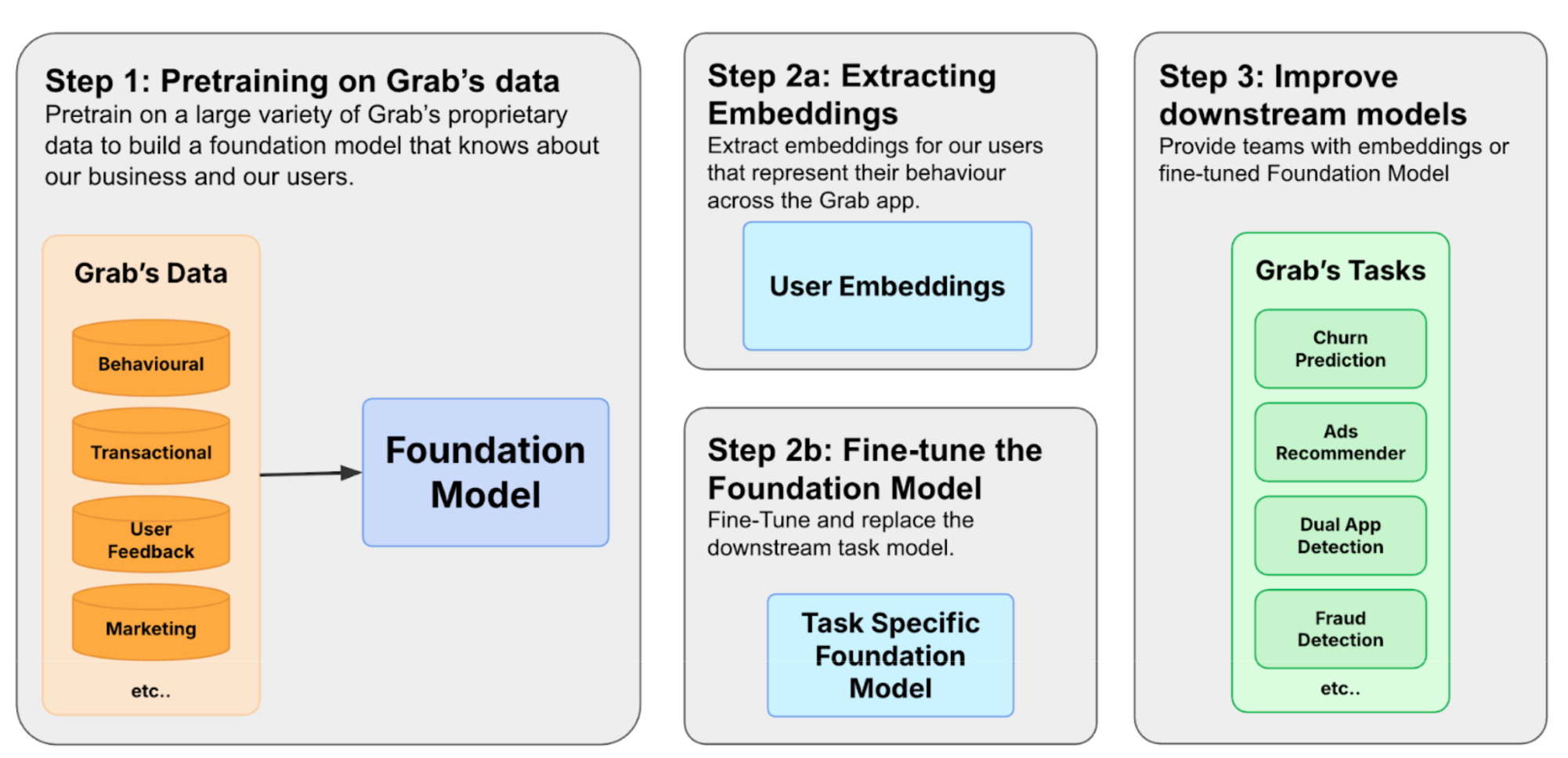
Oxymoron was the first thing that came to my mind when I scanned through the article “User Foundation Models for Grab”. In their figure (Step 2b), they use the term “Task-Specific Foundation Model”. That’s a contradiction.
A foundation model is supposed to be general-purpose (based on how almost everyone uses the term). Task-specific is the opposite of general-purpose. Combining the two terms sounds like a contradiction. Like if I said I wanted to sell you a general-purpose specialized tool.
My initial reaction? This is a large embedding/representational learning model (with multimodality). Dime a dozen. Something that has been around for a while.
This led me down the rabbit hole of going back to a commonly accepted definition of a foundation model.
Foundation model - Back in 2021, Stanford’s HAI defined a model that is trained on broad data, generally using self-supervision at scale, and that can be adapted (e.g., fine-tuned) to a range of downstream tasks as a foundation model.
Embedding model - Embeddings are numerical representations that we learn from data. It can represent text, images, and audio or almost anything (like users in Grab’s case). It can be learnt from multimodal data. Because it represents some underlying meaning (or semantics), we can use them for different downstream tasks as inputs into other models or methods. Kind of like feature engineering, but better. Learning an embedding or representation (even from multiple modalities) for multiple downstream tasks is not usually regarded as a foundation model.
I admit that the line is quite fine, but there is a difference.
Grab’s ‘foundation model’ ingests terabytes of heterogeneous data. Combines user profiles (tabular) with clickstreams (time-series). Trained to predict a user’s next action (e.g., booking a ride or ordering food). And learns the underlying representations of user behavior.
The model can then be used to 1) extract user embeddings from the model or 2) as the base for finetuning a new model for a task.
So I think it could (kind of) qualify as a foundation model as it is 1) trained on broad data; with 2) self-supervision; and 3) can be adapted (fine-tuned) to different tasks.
But the article does not really cover the 3rd point on fine-tuning for different tasks (except that it is one pathway), and focuses on the use of the embeddings.
I like their approach, especially the part about treating sequences of user actions like text, and predicting a user’s next action for self-supervised learning, as well as the value associated with the action. And I’m sure it was no mean feat deploying something like this into production.
So it might not be general purpose like ChatGPT in that it can write poetry, solve math problems and generate code.
But could it be a foundation model in a specific domain? How do we distinguish foundation models from representation learning? Where would you draw the line?
#AI #FoundationModels #AIEngineering #AIInnovation