
LLMs Can't Understand Time, At Least Not Naturally - An Update
Update of an article I did in 2025.

This is an update of an article I did for AI Realist in 2025. Things have shifted so I thought good time for an update. I have also added a list of references for folks who are interested.
When LLMs first became accessible and popular in 2022, one easy way to tell if someone was selling snakeoil was if they claimed that either ChatGPT or LLMs could forecast or predict something in the future. Someone who said that obviously did not understand how LLMs then worked, and were essentially hallucinating or bullshitting with great confidence.
LLMs are trained on text data. To forecast, you are working in the domain of time series data. Text and time series are both sequences, but they have fundamentally different characteristics.
Things have evolved since. Quite a lot actually. I would listen more patiently now for the details if someone said he or she used LLMs for forecasting due to shifts in the field. However, there is still a clear distinction between LLMs for language or text, compared to time series foundational models inspired by LLMs.
Let me explain this. In 4 short acts.
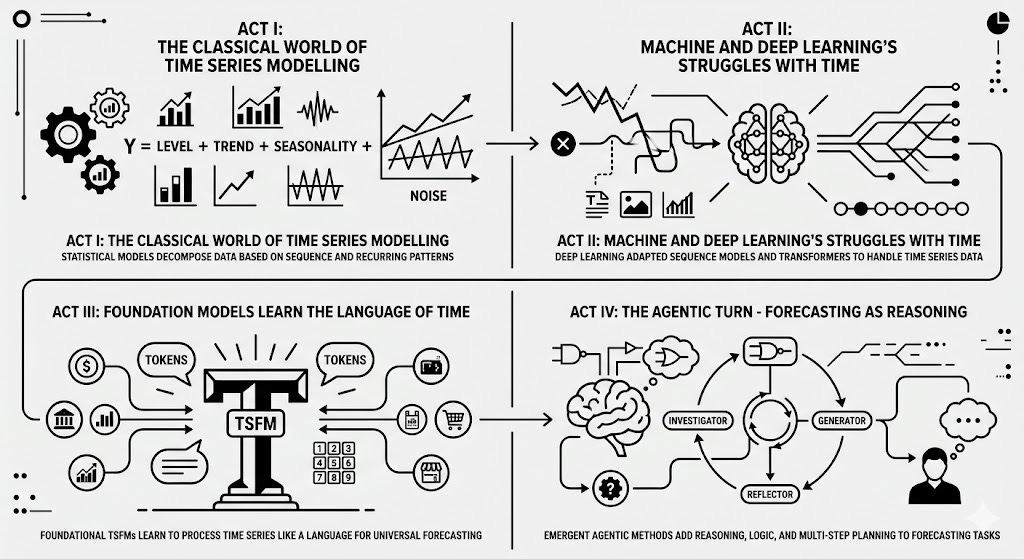
Act I: The Classical World of Time Series Modelling
For decades, way before neural networks were practically usable, forecasting or predictions with time series data was the domain of statisticians and econometricians. Time series data is fundamentally different from tabular, image or text data. You can shuffle rows in tables, mix up images, or rephrase text, and the meaning would still be largely intact.
The first, but not unique, property of time series is sequence. Mixing up the sequential order of time series data renders it meaningless. This is what it has in common with text.
This is the world of models like ARIMA. Understanding such models provides a clear understanding of what matters for time series data.
The AutoRegressive Integrated Moving Average (ARIMA) models and its variants dominated time series analysis for ages. They captured the essential insights needed to analyse or make predictions with time series data.
The core ideas:
AutoRegressive (AR): Current values depend on previous values
Integrated (I): Many series become predictable after differencing
Moving Average (MA): Current values depend on errors of previous predictions
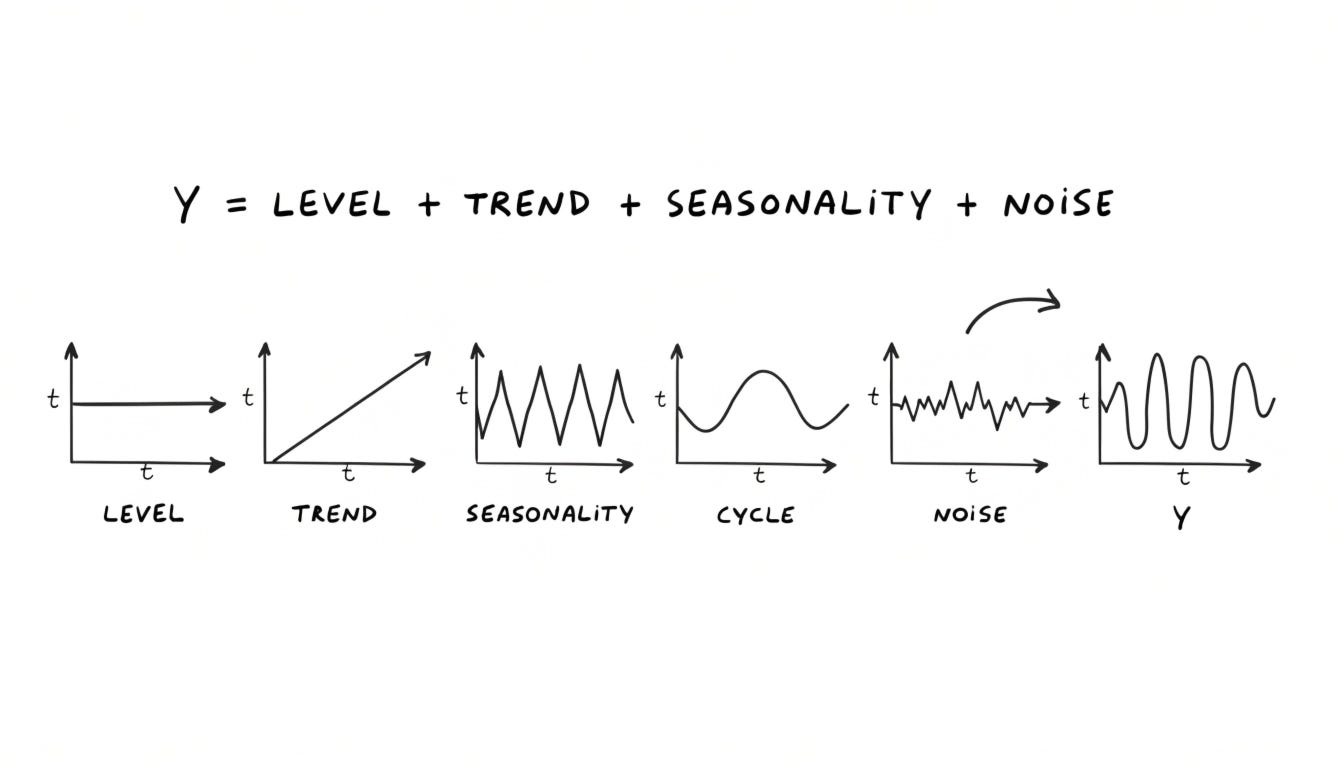
Conceptually, every time series could be understood as a combination of level, trend, seasonality, cycles and some noise. This is what makes it different from text.
Y = LEVEL + TREND + SEASONALITY + NOISE
Seasonal ARIMA (SARIMA) handled recurring seasonal patterns. Vector AutoRegression (VAR) tackled multiple related series. Holt-Winters exponential smoothing handled trends and seasons differently. For volatile financial series, Engle’s ARCH and Bollerslev’s GARCH gave us proper models for time-varying volatility - the technical term is conditional heteroskedasticity, but the everyday intuition is that the size of the typical move on a given day is itself a moving target. Harvey’s structural time series models decompose a series into latent components - level, trend, seasonal, cycle - each modelled as its own stochastic process, with the Kalman filter doing the inference behind the scenes. And modern decomposition extensions like MSTL (Multiple Seasonal-Trend decomposition using Loess) handle multiple seasonalities at once - think hourly demand with daily, weekly, and annual cycles all stacked together.
If you want to start playing with these classical models, R’s forecast package (auto.arima, ets, stl) is the easy on-ramp, and Python’s statsforecast from Nixtla gives you the same family of models. Meta’s Prophet popularised an additive-decomposition approach for forecasting and sits closer to the classical end of the spectrum despite being open-sourced by a deep-learning lab.
Another fundamental characteristic of time series that is critical is the degree of stationarity. Much more than text or images (words only change meaning slowly over time, same for images), time series in many domains continually evolve, and are what we call non-stationary.*
Recall ‘I’ for integration in ARIMA? That step leads to a differencing operation that allows the time series to be more stationary, and hence more predictable.
The classical world of time series forecasting, because of this focus on the underlying patterns of trends, seasons etc., was inherently explainable.
That’s Act I. But before I move on to Act II, I thought it would be useful to mention that forecasting is not the only task you can apply to time series. You can also nowcast (predict current unknown values with time series data to date, like GDP); classify time series patterns, detect outliers for time series, and so on and so forth. But the fundamental characteristics of time series data that need to be taken into account remain the same.
Act II: Machine and Deep Learning’s Struggles with Time
The power of machine learning models in the last decade meant many tried to use machine learning models such as support vector machines, random forests, and boosting tree models for time series forecasting. But these models did not fit naturally with time series data. Not that it could not work, but it was a hit and miss.
The natural question then was, why switch to these significantly more complex machine learning models when the classical models were good enough?
Then came advances in computer vision and natural language processing driven by deep learning. Computer scientists being computer scientists, they started looking for new domains to test these models on. Naturally, given the importance of time series data in many commercial and financial settings, computer scientists started using these models for different tasks on time series data.
But here’s the thing - you can’t just throw time series data at a regular deep learning model and expect magic. Remember the properties - sequence, patterns, stationarity?
Sequence models for natural language processing like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks made a lot of sense. DA-RNN introduced dual-stage attention for input and temporal selection. Time-aware LSTMs handled irregular sampling via decay gates. Temporal Convolutional Networks showed that convolutional architectures could match or beat RNNs for many sequence tasks.
Answering the question of how to remember important information from way back in the sequence, while forgetting irrelevant noise applied equally to text and time series data.
There were many papers that focused on adapting RNNs, LSTMs, and even CNNs (designed for image data) to time series data. I would say the results were ambivalent. Sometimes you got fantastic results, sometimes a simple classical model would beat the complex deep learning model handily in a fraction of the time and computing power. A reviewer once asked me why a model I developed and trained for time series modelling was so large in size. It was only 12m parameters (miniscule compared to the billions and trillions for LLMs), but you get the idea. Probabilistic recurrent forecasters like DeepAR and deep state-space variants became quite popular. NeuralProphet - the DL successor to Meta’s Prophet, swapping the additive components for neural network blocks - sounded promising but empirically failed to beat plain ETS on standard benchmarks. The “DL doesn’t automatically win” pattern was already showing up.
So was it a pointless exercise? Not really.
One of the key differences between classical and deep learning time series models was that deep learning models could utilise multimodal time series data (time series of text, audio, sensor events, images, networks), whereas classical models were largely restricted to numerical time series.
There are also many other aspects of time series that we could focus on aside from sequence for time series, distinctly different from natural language or image data.
For example:
Different time scales: Time series that change by the second, hourly, daily, quarterly and so on and so forth.
Varying signal quality: Time series data that are inherently noisier than natural language or image data.
Relationship dynamics: The importance of interactions between different time series.
There are many more. And deep learning models gave us a lot of flexibility to explore these characteristics.
In the early 2020s, even before ChatGPT, but after the seminal “Attention is All You Need” moment, many papers also explored the use of attention-based transformers for time series data.
It was a logical pairing. We use positional encodings to encode the position of tokens (or words) in transformers for text. Why couldn’t we do the same for time series steps?
A whole family came out of this - N-BEATS for interpretable basis expansion, the Temporal Fusion Transformer (TFT) for multi-horizon attention, Informer for long sequences, TS Transformer for self-supervised representation learning, Autoformer for decomposition + auto-correlation, and PatchTST. The PatchTST trick - that you can chop a series into patches and treat them like tokens - would turn out to be a conceptual seed for Act III. CoST pushed contrastive disentanglement of seasonal and trend representations.
In parallel, multimodal work fused text and prices for financial forecasting - event-driven stock prediction such as “Listening to Chaotic Whispers”, which added news attention. Fine-grained event typologies, stock embeddings from news + price history, hierarchical multi-task models for earnings-call volatility, REST’s relational event-driven framework, and FAST’s news-and-tweet time-aware network all extended this line.
I published several papers in this domain - using numerical and text time series with evolving networks. KECE combined knowledge graphs with numerical and textual time series. GLAM distinguished between global and local temporal patterns with adaptive curriculum learning to handle noise. GAME designed latent sequence encoders for multimodal data of different frequencies. DynMix used dynamic self-supervised learning with implicit and explicit network views, while DynScan learned slot concepts to handle non-stationary multimodal streams. These models showed strong results on financial forecasting, portfolio optimization, and ESG predictions, but they were highly specialized transformer models trained for specific tasks.
They were not general purpose or foundational models. Just using a transformer does not qualify. A general purpose or foundational model needs to be usable across different tasks.
But there were folks already researching these, even prior to ChatGPT coming onto the scene in 2022.
For readers who want to play with this era of models, the Python libraries darts (which also contains classical models), Nixtla’s neuralforecast, and HuggingFace’s transformer-based time-series pipelines are good entry points.
Act III: Foundation Models Learn the Language of Time
Interestingly, while I was researching multimodal time series models focused on networks, one of my PHD mates (Gerald Woo) was doing groundbreaking work on one of the first foundational models for time series data inspired by LLMs architectures.
This was the Moirai time series foundation model for universal forecasting. We attended each other’s research presentations once in a while, and I found his work fascinating. But I was already at the tail end of my PHD, so too late to switch tack.
Since then there have been many more foundational models for time series data inspired by LLMs architectures.
Now that you know all the special characteristics of time series, you would know that one cannot just throw a time series model into a transformer or an LLM and expect some magic to happen.
One key challenge was how to convert infinite numerical possibilities into a finite vocabulary that transformers can process. Language has a finite vocabulary, but not time series.
Different teams solved this differently:
Amazon’s Chronos quantizes continuous values into 4,096 discrete bins - essentially creating a “vocabulary” for time series. Google’s TimesFM treats time segments as “patches” like image processing. Salesforce’s MOIRAI uses multiple patch sizes for different temporal frequencies. There are other such models, but the fundamental issues being solved are similar. Address the tokenisation of time series, collate a large cross domain dataset, adjust the transformer architecture to address the unique characteristics of time series data.
In the months since the first version of this piece, the foundation-model wave has not slowed. But the field has clearly forked into two camps. Both are still very much “Act III” - they tokenize numerical time series and stick a transformer on top. They differ in where the parameters come from.
Camp A - Tokenize numbers, train a transformer from scratch.
This is the original recipe. The more recent successors mostly keep it and refine it:
Chronos-2 - Amazon’s 2025 follow-up; adds in-context learning across related series and covariate-informed forecasting.
ChronosX - extends Chronos to handle exogenous variables.
MOIRAI-2 - simpler architecture, better data, generalises better than v1.
MOIRAI-MoE - sparse mixture-of-experts variant; specialises across frequencies.
Lag-Llama - open-source probabilistic TSFM.
TimeGPT-1 - Nixtla’s offering.
Camp B - Don’t pretrain a TSFM. Reprogram a frozen LLM.
The intuition: LLMs already cost hundreds of millions to train. Maybe you don’t need to start from scratch - just teach the existing LLM to see numbers.
Time-LLM - patches the series, reprograms each patch via cross-attention with text prototypes, freezes the LLM body, trains only the input projection and output head.
LLMTime - encodes the series as a string of digits and lets the LLM autoregress. No training.
GPT4TS / OFA - frozen GPT-2, fine-tune only the layer norms and positional embeddings.
PatchInstruct - patch tokenisation + decomposition + neighbour augmentation as a prompting strategy.
What’s the point of foundational models for time series?
To me, the holy grail is probably few or zero-shot forecasting. Train once on massive time series datasets, then gain the ability to perform a range of tasks - forecast sales, detect equipment anomalies, or classify patterns across entirely new domains without additional training.
Still an unsolved problem I feel.
The key characteristics of time series data that we mentioned earlier are still key (such as sequence dependency, non-stationarity, varying frequencies, signal-to-noise ratios, and domain-specific patterns), and unlike text data, the nature of time series data in different domains (finance, healthcare, energy, retail, manufacturing, climate) can be vastly different and evolve significantly across time. We will talk a bit more about this below.
Act IV: The Agentic Turn - Forecasting as Reasoning
Acts I, II, and III all share an assumption. They assume forecasting is a single step problem. You feed in history, the model spits out the forecast or prediction.
The new wave has a few branches.
First, we can fuse different types of time series data at foundational model level across steps. From News to Forecast uses LLM agents to iteratively filter news, classify events by effect horizon, and fine-tune an LLM to emit digit sequences alongside a reflection loop.
Second, we can add reasoning. Training LLMs showed that reasoning at inference time - generating long chains of thought before producing an answer - improves performance on maths and code. Does it improve performance on time-series forecasting? TimeReasoner wraps series + timestamps + contextual features into a hybrid prompt, feeds it to a slow-thinking LLM, and explores three reasoning strategies - making the LLM think about the series before answering.
And finally, add multiple steps to the mix. AlphaCast - a training-free three-stage workflow (Investigator → Generator → Reflector) that mirrors how an expert forecaster works: prepare context, predict, critique, refine.
Conclusion
The only conclusion is that there is no conclusion yet. The jury is still out.
For a long time, a good place to look at the state of time series models were the Makridakis Competitions. M1-M3 (1980s-90s) were won by classical methods. M4 (2020) was won by Slawek Smyl’s hybrid ES-RNN - exponential smoothing married to LSTM - not by pure deep learning. M5 (2022) was won by LightGBM (gradient-boosted trees) with feature engineering, not deep architectures. M6 (2025) pushed into finance and reported that most teams underperformed simple benchmarks. The recurring lesson across forty years of competitions: the gains attributed to deep learning are usually gains from feature engineering, ensembling, or hybrid approaches. A example of a new leaderboard for foundation models is GIFT-Eval - 24 datasets over 144,000 time series and 177 million data points, spanning seven domains, 10 frequencies, multivariate inputs, and prediction lengths ranging from short to long-term forecasts.
But even when these foundation models top the leaderboards, the picture could be misleading.
Rethinking Evaluation in the Era of TSFMs found that benchmark scores are inflated - the test data often overlaps with the training data, either directly or because similar time periods appear in both. Strip the overlap out and the impressive numbers shrink.
Re(Visiting) TSFMs in Finance put the leading foundation models against decades of stock returns from markets around the world. The result: off the shelf, they did not beat ordinary baselines. Even fine-tuning didn’t close the gap. The only thing that worked was re-training the model from scratch on financial data - at which point you’ve essentially built a domain-specific model, not used a “foundation” one.
Multimodal and agentic forecasting are even harder to judge. Rethinking Multimodal TSF Evaluation points out that many “text helps forecasting” benchmarks are flawed - for example, the news used in testing has often already leaked into the model’s training data.
And that’s where we are now. Lots of progress, but still many open questions and uncertainties.
References
Act I - Classical time-series models, surveys, and competitions
Forecasting: Principles and Practice - https://otexts.com/fpp3/ - Modern, accessible, free treatment of the whole classical lineage. Best starting point.
Automatic Time Series Forecasting: The
forecastPackage for R - https://www.jstatsoft.org/v027/i03 - *Origin ofauto.arima.Forecasting Seasonals and Trends by Exponentially Weighted Moving Averages - https://www.sciencedirect.com/science/article/abs/pii/S0169207003001134
Exponential Smoothing: The State of the Art - Part II - https://www.bauer.uh.edu/egardner/3301H%20Operations%20Management/ESG%20Publications/2006%20Exp.%20Sm.%20State%20of%20the%20art%20-%20Part%20II.pdf.
Macroeconomics and Reality - https://www.pauldeng.com/pdf/Sims%20macroeconomics%20and%20reality.pdf
Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of UK Inflation - https://www.jstor.org/stable/1912773
The Story of GARCH: A Personal Odyssey - https://public.econ.duke.edu/~boller/Papers/GARCH_JoE_2023.pdf .
Forecasting, Structural Time Series Models and the Kalman Filter - https://www.cambridge.org/core/books/forecasting-structural-time-series-models-and-the-kalman-filter/CE5E112570A56960601760E786A5E631
MSTL: A Seasonal-Trend Decomposition Algorithm for Time Series with Multiple Seasonal Patterns - https://arxiv.org/abs/2107.13462
StatsForecast / Nixtla - https://github.com/Nixtla/statsforecast
The M4 Competition: 100,000 time series and 61 forecasting methods - https://www.sciencedirect.com/science/article/abs/pii/S0169207019301128
The M5 Accuracy Competition: Results, Findings and Conclusions - https://www.sciencedirect.com/science/article/pii/S0169207021001874
Forecasting with Gradient Boosted Trees: M5 Uncertainty Winner - https://www.sciencedirect.com/science/article/abs/pii/S0169207021002090
The M6 Forecasting Competition: Bridging the Gap between Forecasting and Investment Decisions - https://arxiv.org/abs/2310.13357
Act II - RNN / LSTM / Transformer-era and multimodal cluster
DA-RNN: Dual-Stage Attention-Based RNN - https://arxiv.org/abs/1704.02971
Patient Subtyping via Time-Aware LSTM Networks (T-LSTM) - https://dl.acm.org/doi/10.1145/3097983.3097997
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling (TCN) - https://arxiv.org/abs/1803.01271
DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks - https://arxiv.org/abs/1704.04110
Deep State Space Models for Time Series Forecasting - https://papers.nips.cc/paper/2018/hash/5cf68969fb67aa6082363a6d4e6468e2-Abstract.html
NeuralProphet: Explainable Forecasting at Scale - https://arxiv.org/abs/2111.15397
A Hybrid Method of Exponential Smoothing and Recurrent Neural Networks for Time Series Forecasting (ES-RNN, M4 winner) - https://www.sciencedirect.com/science/article/abs/pii/S0169207019301153
N-BEATS: Neural Basis Expansion Analysis for Interpretable Time Series Forecasting - https://arxiv.org/abs/1905.10437
Temporal Fusion Transformers for Interpretable Multi-Horizon Time Series Forecasting (TFT) - https://arxiv.org/abs/1912.09363
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting - https://arxiv.org/abs/2012.07436
A Transformer-based Framework for Multivariate Time Series Representation Learning - https://arxiv.org/abs/2010.02803
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers (PatchTST) - https://arxiv.org/abs/2211.14730
CoST: Contrastive Learning of Disentangled Seasonal-Trend Representations for Time Series Forecasting - https://arxiv.org/abs/2202.01575
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting - https://arxiv.org/abs/2106.13008
Deep Learning for Event-Driven Stock Prediction - https://www.ijcai.org/Proceedings/15/Papers/329.pdf
Listening to Chaotic Whispers: A Deep Learning Framework for News-Oriented Stock Trend Prediction - https://arxiv.org/abs/1712.02136
Incorporating Fine-grained Events in Stock Movement Prediction - https://aclanthology.org/D19-5106/
Stock Embeddings Acquired from News Articles and Price History, and an Application to Portfolio Optimization - https://aclanthology.org/2020.acl-main.307/
HTML: Hierarchical Transformer-based Multi-task Learning for Volatility Prediction - https://dl.acm.org/doi/10.1145/3366423.3380128
REST: Relational Event-driven Stock Trend Forecasting - https://arxiv.org/abs/2102.07372
FAST: Financial News and Tweet Based Time Aware Network for Stock Trading - https://aclanthology.org/2021.eacl-main.185/
Learning Knowledge-Enriched Company Embeddings for Investment Management - https://dl.acm.org/doi/abs/10.1145/3490354.3494390
Investment and Risk Management with Online News and Heterogeneous Networks - https://dl.acm.org/doi/full/10.1145/3532858
Guided Attention Multimodal Multitask Financial Forecasting - https://aclanthology.org/2022.acl-long.437/
Dynamic Multimodal Implicit and Explicit Networks for Multiple Financial Tasks - https://ieeexplore.ieee.org/abstract/document/10020722/
Dynamic Multimodal Slot Concepts from the Web - https://dl.acm.org/doi/full/10.1145/3663674
Act III - Foundation models (Camp A: train-from-scratch TSFMs)
Unified Training of Universal Time Series Forecasting Transformers (MOIRAI) - https://arxiv.org/abs/2402.02592
Chronos: Learning the Language of Time Series - https://arxiv.org/abs/2403.07815
A Decoder-Only Foundation Model for Time-Series Forecasting (TimesFM) - https://research.google/blog/a-decoder-only-foundation-model-for-time-series-forecasting/
Chronos-2: From Univariate to Universal Forecasting - https://arxiv.org/abs/2510.15821
ChronosX: Extending Time-Series Foundation Models to Support Exogenous Variables -

MOIRAI 2.0: When Less Is More for Time Series Forecasting - https://arxiv.org/abs/2511.11698
MOIRAI-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts - https://arxiv.org/abs/2410.10469
Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting - https://arxiv.org/abs/2310.08278
TimeGPT-1 - https://arxiv.org/abs/2310.03589
Act III - Foundation models (Camp B: LLM-reprogramming)
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models - https://arxiv.org/abs/2310.01728
Large Language Models Are Zero-Shot Time Series Forecasters (LLMTime) - https://arxiv.org/abs/2310.07820
One Fits All: Power General Time Series Analysis by Pretrained LM (GPT4TS / OFA) - https://arxiv.org/abs/2302.11939
PatchInstruct: Forecasting Time Series with LLMs via Patch-Based Prompting and Decomposition - https://arxiv.org/abs/2506.12953
Act IV - Multimodal text + TS
From News to Forecast: Integrating Event Analysis in LLM-Based Time Series Forecasting with Reflection - https://arxiv.org/abs/2409.17515
Unlocking the Value of Text: Event-Driven Reasoning and Multi-Level Alignment for Time Series Forecasting - https://arxiv.org/abs/2603.15452
Act IV - Agentic & reasoning frameworks
AlphaCast: A Human Wisdom-LLM Intelligence Co-Reasoning Framework for Interactive Time Series Forecasting - https://arxiv.org/abs/2511.08947
Empowering Time Series Forecasting with LLM-Agents (DCATS) - https://arxiv.org/abs/2508.04231
Can Slow-Thinking LLMs Reason Over Time? Empirical Studies in Time Series Forecasting (TimeReasoner) - https://arxiv.org/abs/2505.24511
Evaluation
GIFT-Eval: A Benchmark for General Time Series Forecasting Model Evaluation - https://arxiv.org/abs/2410.10393 · leaderboard at https://tsfm.ai/benchmarks/gift-eval
Rethinking Evaluation in the Era of Time Series Foundation Models: (Un)known Information Leakage Challenges - https://arxiv.org/abs/2510.13654
Rethinking Multimodal Time-Series Forecasting Evaluation - https://openreview.net/forum?id=Z1TMV4bGuu
Re(Visiting) Time Series Foundation Models in Finance - https://arxiv.org/abs/2511.18578