
Cache for cash.
Prompt caching reuses past calculations on your prompts to save money. How does it work?

Going to try a simplified TLDR on it that will take 2 minutes of your time.
Just 3 concepts.
---
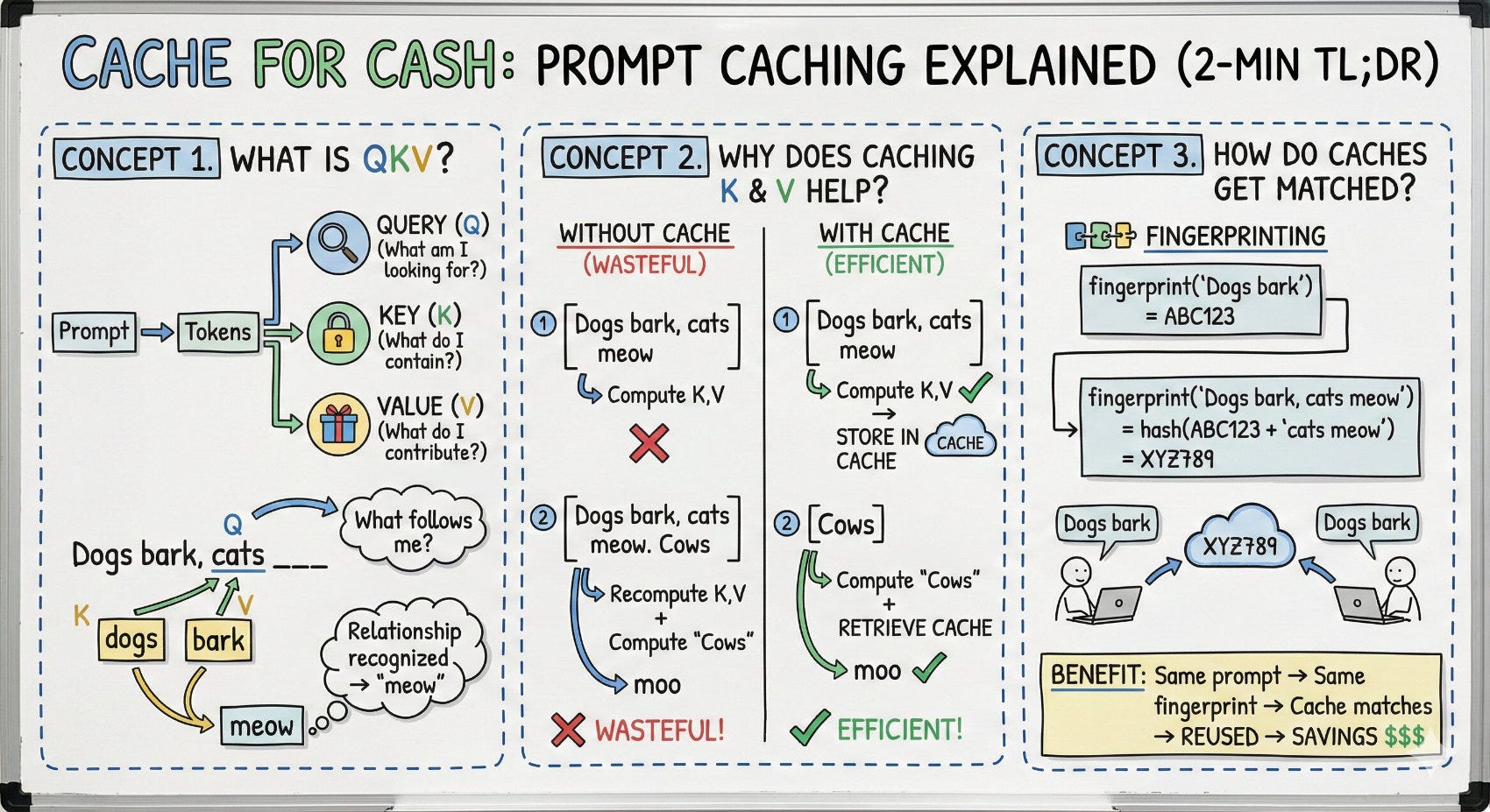
Concept 1. What is QKV?
QKV is the fundamental operation in attention. Your prompt → converted and split into tokens.
Every token produces three vectors:
Query (what am I looking for?)
Key (what do I contain?)
Value (what do I contribute?)
Example: “Dogs bark, cats ___”
When processing “cats”, it creates a Query that asks “what’s relevant to me?”
Keys from earlier tokens answer. “dogs” and “bark” are relevant.
Their Values get pulled in, enriching “cats” with context.
The enriched representation then predicts → “meow”
---
Concept 2. Why does caching K & V help?
We don’t want to recompute K and V that already exist, so we cache them.
Example without cache (wasteful):
Step 1: Compute K,V for [Dogs bark, cats meow] → ...
Step 2: Compute K,V for [Dogs bark, cats meow. Cows] → moo
Computing K,V for [Dogs bark, cats meow] twice is wasteful.
Example with cache (efficient):
Step 1: Compute K,V for [Dogs bark, cats meow] → cache it
Step 2: Compute K,V for [Cows] only → append to cache → moo
Caching in Step 1 allows us to reuse it in Step 2.
---
Concept 3. How do caches get matched?
Fingerprinting with memory.
fingerprint(”Dogs bark”) = ABC123
fingerprint(”Dogs bark, cats meow”) = hash(ABC123 + “cats meow”) = XYZ789
Each fingerprint bakes in everything before it. If XYZ789 matches, ABC123 matches too.
Benefit: Same prompt across users → same fingerprint → cache matches → cache reused → savings.
Did I succeed in explaining this in 2 minutes?
#AI #LLM #Cache #AIEducation