
Thinking in AI | An AI Model is Just Math
Deconstructing AI

Before we get down to the key focus of this series of articles, on data types and tasks in AI, let’s take a step back by getting a quick intuitive understanding of what is probably the most core element in AI - the model.
As mentioned in the prior article, most of the concepts in this series are not new, especially to AI researchers or practitioners, but I hope sharing the way I think about them might be useful to readers who are not as familiar with AI.
There is this tendency to think of a model (AI or not) as this opaque black box. But if we look under the hood of an AI model or even a Generative AI model, it really is just math. And if one strips away some of the more complex features, the core part of an AI model isn’t even really that difficult to understand.
We are going back to basics and starting with this topic because understanding how an AI model works in an intuitive manner, rather than treating it as a black box, is critical in understanding how AI (and Generative AI) interact with different data types and tasks, and how to think in AI.
The simple line
Remember learning about the equation that describes a line in school? The simple equation Y=AX+B describes a relationship – how the value of Y changes with X, with A describing the slope of the line, and B the intersection of the line with the Y axis.
But how do we get A and B so that we know the relationship between Y and X. That is the core objective of linear regression. Understanding how this works serves as a key gateway to understanding many (but maybe not all) AI models.
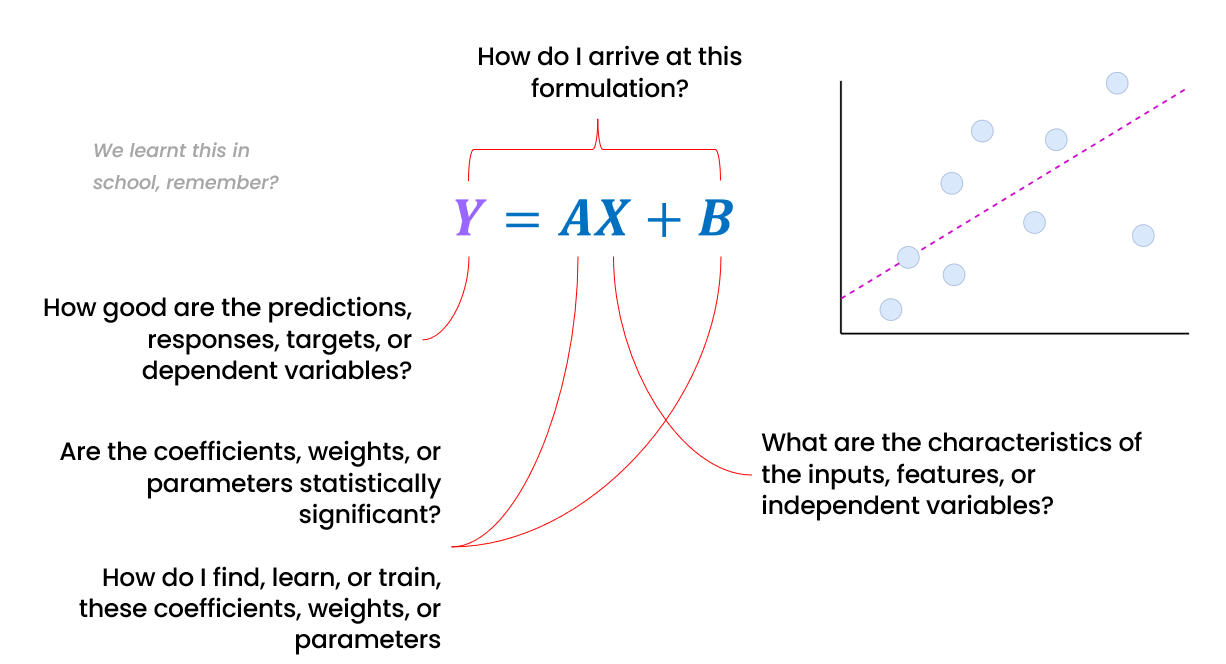
We can frame the really simple linear regression line as an AI model (not that we would actually use it as an AI model), and you can see how the different parts of a linear regression "model" link to key AI (or even statistical) concepts above.
The key point to note is that the linear regression processes the input X, using the weights A and B, to generate the output Y.
Deconstructing AI
Finding the optimal A and B for a linear regression that best describes the relationship between Y and X is analogous to training a complex AI model and learning the optimal weights for the AI model, so that it learns to recognize complex patterns or relationships to make predictions, or in the case of Generative AI, to generate text or images.
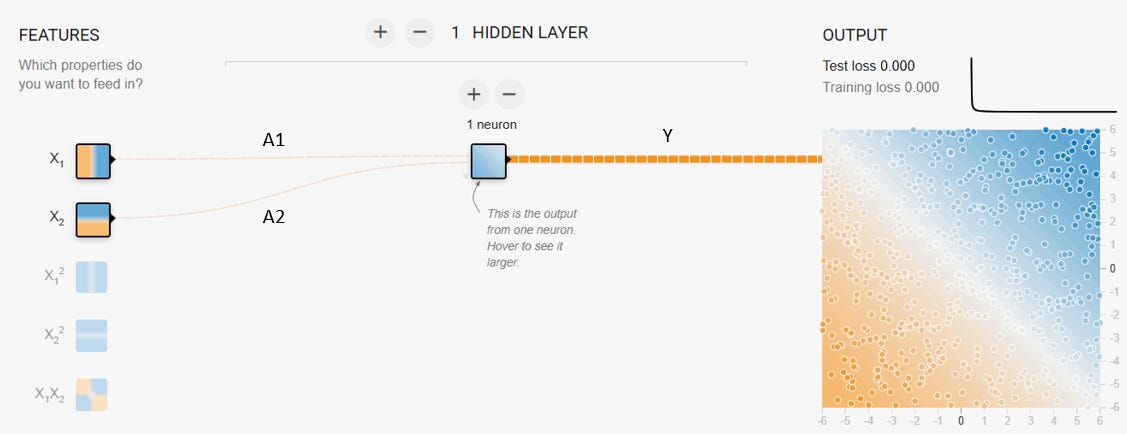
In fact, you can easily simplify a neural network so that we get a linear regression. If you use the neural network simulator at https://playground.tensorflow.org/, you can simplify the neural network to (almost) replicate a linear regression (see the diagram below). The only difference here is that we have two inputs X1 and X2 instead of just one X, and there is a transformation of the output at the end with a separate function called an activation function (not shown below, but almost always present in neural networks). The links between X1 and X2 to the neuron are essentially the weights (A1 and A2 here instead of just A), so Y = A1X1 + A2X2.
So, how does an AI model "learn" the best values for weights such as A and B? It’s not about consciousness; it’s just about optimizing the model.
And optimizing the model is really just finding the best combination of these weights for a specific task.
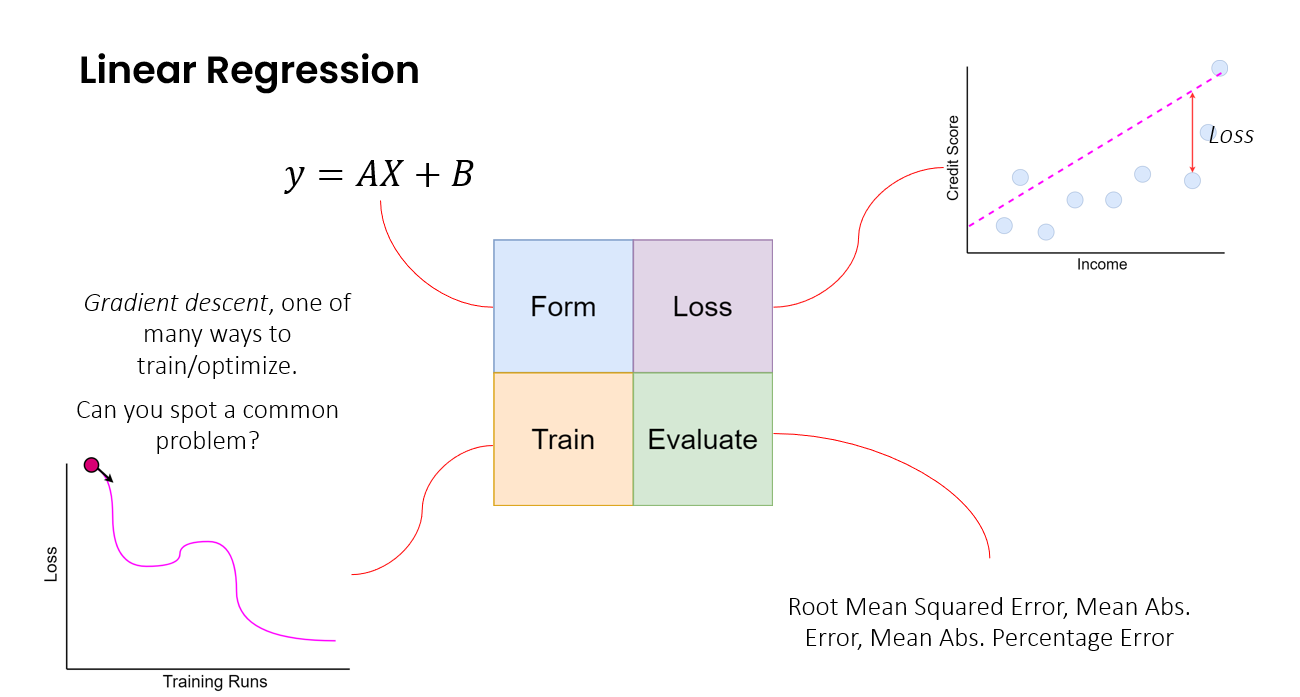
A linear regression does it by fitting the line to the data. Let’s break this down into a simple 4 part framework and relate it to the simple linear regression.
What is the form of the model? What is the function or structure that we use to describe the model? In the case of linear regression, we use the equation Y=AX + B.
What is the loss that we use to train or fit the model? How do we measure the difference between what the model generates as the output, and what the actual output should be? In the case of linear regression, we measure the difference between the value of the actual data (blue dots below), and the predicted value read off the linear regression line.
How do we train the model to minimize this loss? How do we learn the weights or parameters that best fit the model to the data? In the case of linear regression, we try to learn the weights or parameters A and B. One simple way of doing so is iteratively adjusting A and B until one gets the optimal combination of A and B that minimizes the loss we touched on just before this. There are of course smarter ways to do this.
Finally, how do we evaluate how well the model works? We need to evaluate it on data it has not seen to ensure it has learned something (and not just memorized patterns in the training data). In the case of linear regression, we could evaluate it with the loss we used to train the linear regression. But we could also easily choose another measure or metric based on what we are using the model for. Some of these metrics are shown in the diagram below.
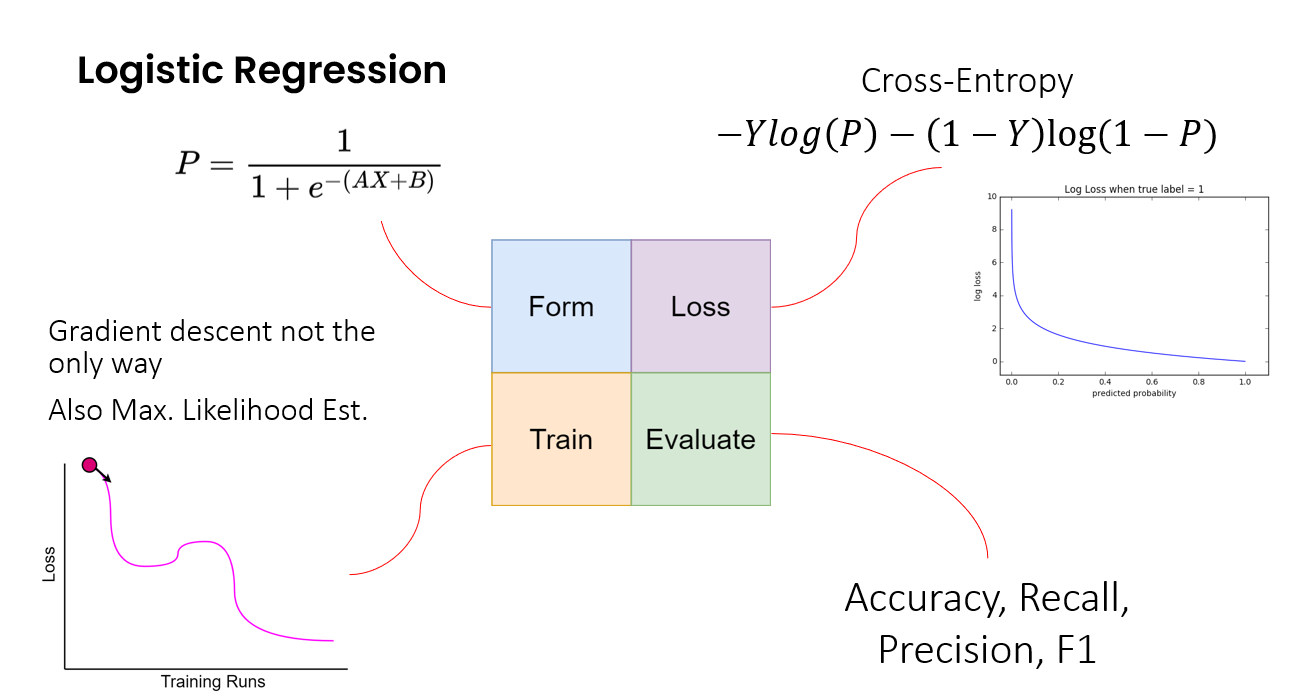
This framework can be extended to not just understand linear regression but many other machine learning models - say logistic regression or even support vector machines used for classification problems.
Now one may wonder, what does this have to do with AI? Well, machine learning is part of AI. And we can easily extend this to neural networks, which are deep learning AI models that underpin most of the cutting edge AI and Generative AI models currently.
Extending the framework to neural networks
So, can this really simple 4-part framework (Form, Loss, Train, Evaluate) help us understand something that seems to be infinitely more complex, like a neural network? It can. Surprisingly well.
Neural networks, which form the backbone of deep learning, might seem really obtuse, but they are built from relatively simple components. We saw earlier that a linear regression can be viewed as a very simple neural network. And we can view it within this 4 part framework as well.
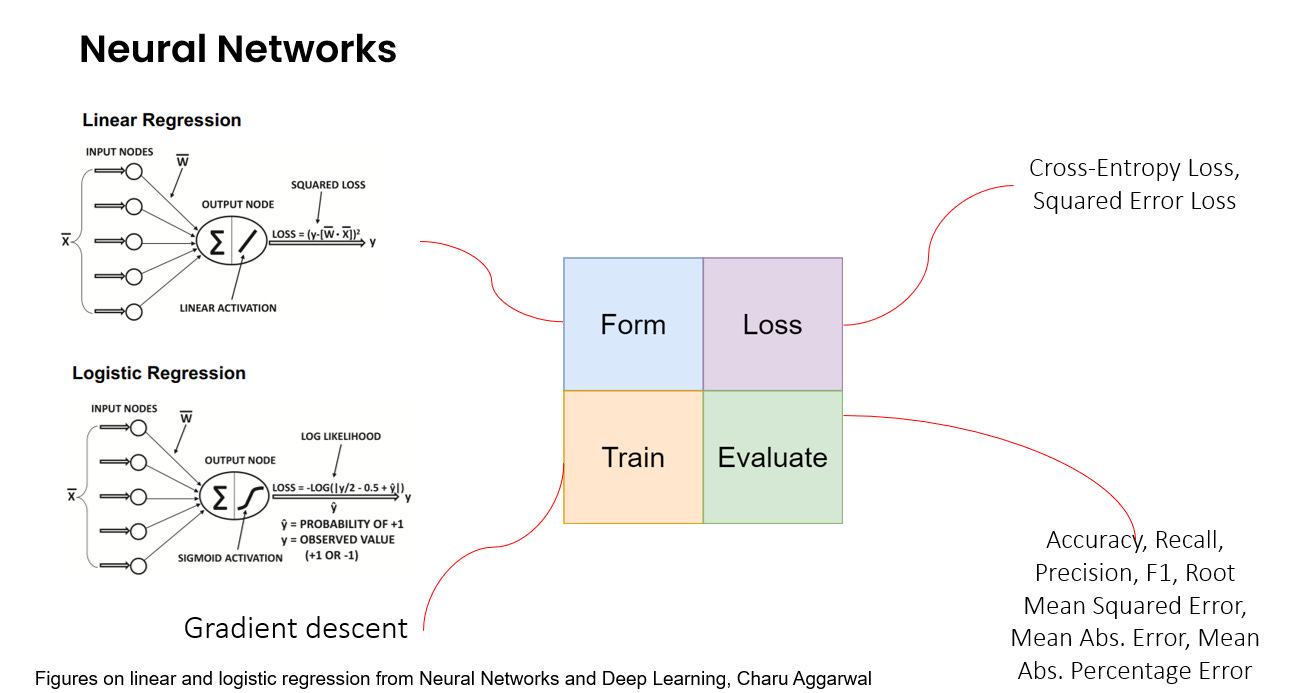
Think of a basic neural network as layers of interconnected nodes (or neurons). Data flows in, passes through these layers, is transformed, and an output comes out the other end. Let’s apply our framework:
Form: Instead of a single equation like Y=AX+B, which can be viewed as a single layer of neurons, the neural network has many many more layers of neurons. Each connection between neurons has a weight (think of these as the "A"s and "B"s). Each neuron sums up the signals coming from its weighted connections and then applies a simple function called an activation function that transforms it further. These layers of neurons and their activation functions, when arranged in specific ways (the model architecture) can model incredibly complex, non-linear patterns in data – far beyond what a simple linear regression line can do.
Loss: We still need a loss function to mathematically quantify how far the neural network’s output is from the actual value. This could be identical to what we use for simpler machine learning models or even linear regression.
Train: This is where some of the additional complexity lies, but the principle is the same: minimize the loss by adjusting the weights or parameters. This is where we use methods such as gradient descent and back-propagation, which are essentially smarter techniques that help us to figure out how to adjust each weight to reduce the overall loss.
Evaluate: And just like before, once the neural network is trained, we need to evaluate its performance on data it hasn’t seen before, and an evaluation metric relevant to the task needs to be selected.
There are many different neural network-based models - from recurrent neural networks to convolutional neural networks to attention-based transformers. However, while each of these neural networks have different model architectures (the form), the basic way in which we develop them (loss, train, evaluate) can be quite similar.
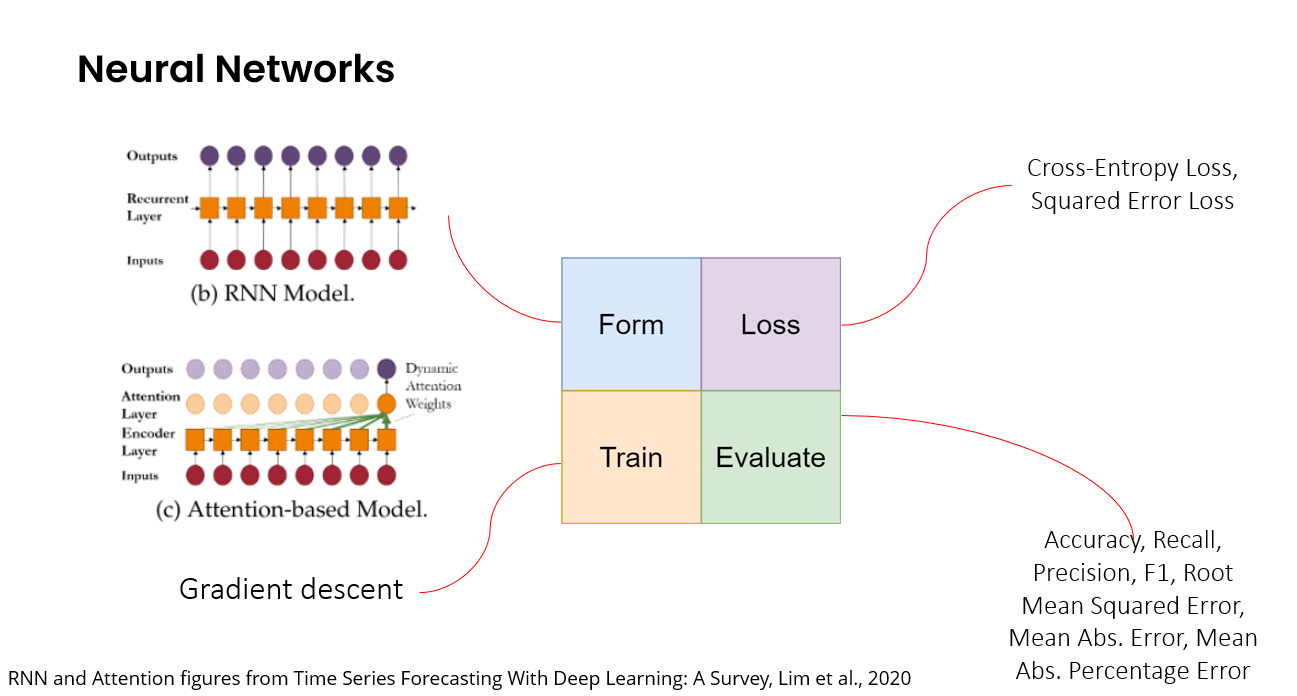
From neural networks to Generative AI
Even the huge models driving modern Generative AI, such as the Large Language Models (LLMs) based on model architectures like the transformer, operate on these same principles. They are essentially very large, specialized neural networks:
Their form is usually some variant of the transformer architecture that works really well for text data.
The loss function is usually based on how well the model approximates the real distribution of text, or how well it predicts the next word in a sequence or a masked word in a sentence based on the context.
They are trained using very large datasets and specialized optimization techniques.
And they are evaluated using a range of metrics and datasets that have been developed for LLMs.
Interestingly, the way in which large language models (LLMs) are trained can be framed as different tasks. In the figure below, we can already observe two specific points relating to data and tasks that we will go deeper into in the subsequent articles.
Text is sequential, order matters. Context also matters. The same word, when surrounded by different groups of words, can mean very different things.
We can train LLMs by predicting masked words. While this seems simple, this simple task of being able to predict masked words can be framed as many other tasks - predicting sentiment, translation, as well as answering questions. This is one of the reasons why LLMs seem to perform so well as a general purpose model.

When we understand LLMs in this way, some claims that have emerged from the hype can seem quite strange. For example, when some people start claiming that we can use LLMs to forecast stock market prices. You could certainly claim that LLMs are excellent at discerning patterns in say, financial news, but to claim that we need to be wary of LLMs causing market turmoil because everyone is using them to forecast stock market prices is perhaps taking this a little too far, once you understand the underlying mechanics of such models.
Moving on with this understanding of AI
Whether it’s fitting a line through data points with linear regression or training a massive LLM with massive amounts of information, the underlying process is quite similar. Whether this entails some form of consciousness or not is beyond the scope of this series of articles, but I find this way of viewing AI or Generative AI more useful when thinking about how to apply them to specific tasks. Now, we’re ready to explore our main topic - thinking in AI through the lens of data types and tasks - in the next set of articles.
Epilogue: While the way in which I described models above seems to suggest that models are tightly intertwined with both the data type and task, there is actually significant flexibility in how one can adapt models for different data types and tasks, particularly for deep learning models. For example, one of my favorite approaches in my research papers was to see how one could combine the attention mechanisms in transformers with memory in recurrent neural networks with the aggregation and message passing mechanisms in graph neural networks so that I could use them for sequences of networks. And these models could be easily adapted for different or even multiple tasks with a simple change in the final few layers of the neural networks. Let us revisit this after the next few articles on data types and tasks.