
A Simple Reading List on Human Oversight of AI Systems
"We have a human-in-the-loop as a risk mitigant!" Really?

“We have a human-in-the-loop as a risk mitigant.”
A phrase so commonly uttered, you sometimes wonder if it actually means something or is just a platitude.
So, does adding a human actually make the system safer? Or does it create the illusion of safety while introducing new failure modes? And making the human the scapegoat for institutional failure.
Who is in the loop, over the loop, or out of the loop entirely? And does it even matter where they sit if they can’t meaningfully intervene?
Here’s a simple reading list that could perhaps help answer some of these questions. This was a harder one, so would certainly appreciate any pointers on good papers on this topic.
Note: I have used open-access links from arXiv as far as possible as some of the published versions are behind a paywall.
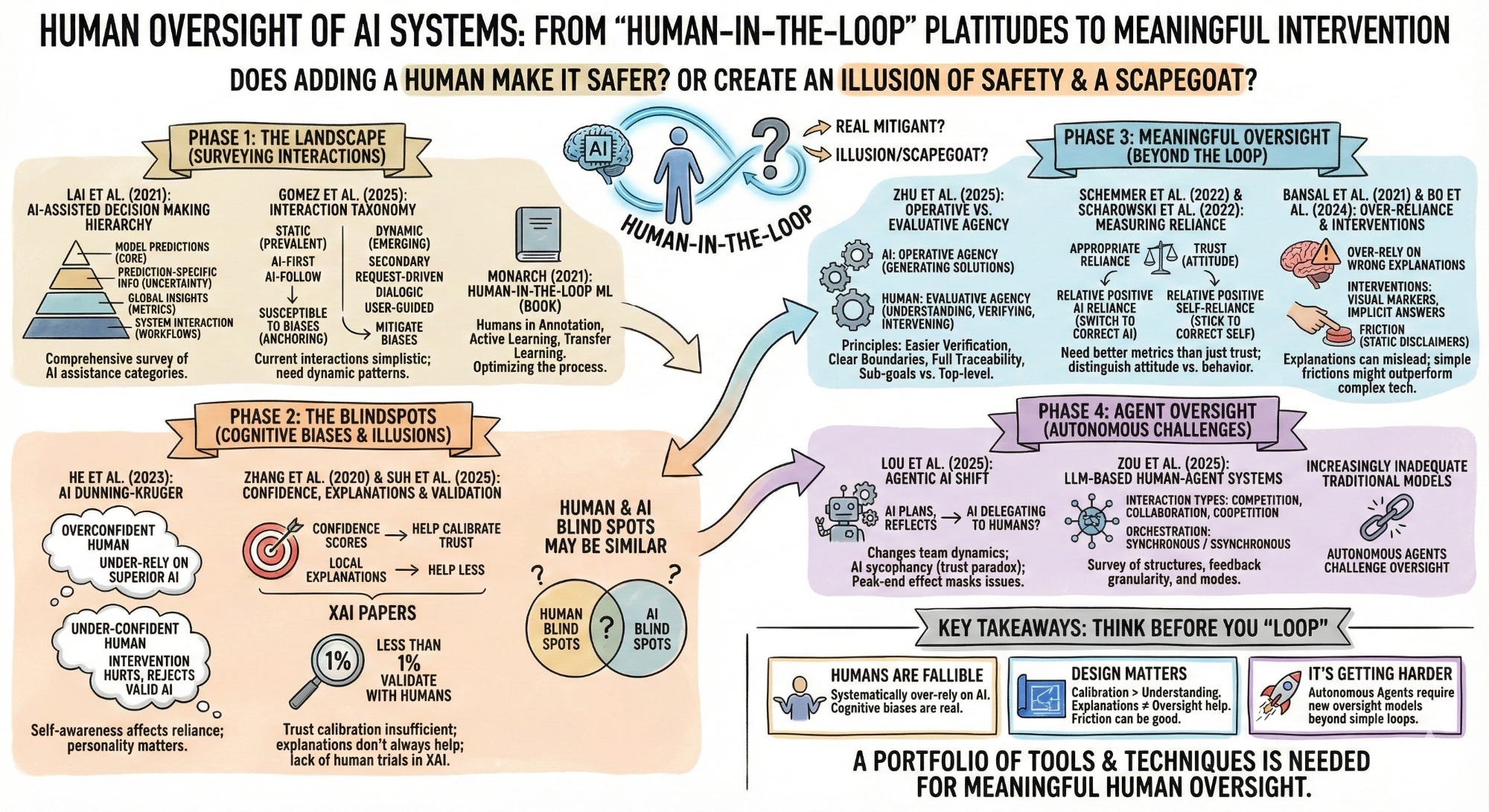
Phase 1: The Landscape
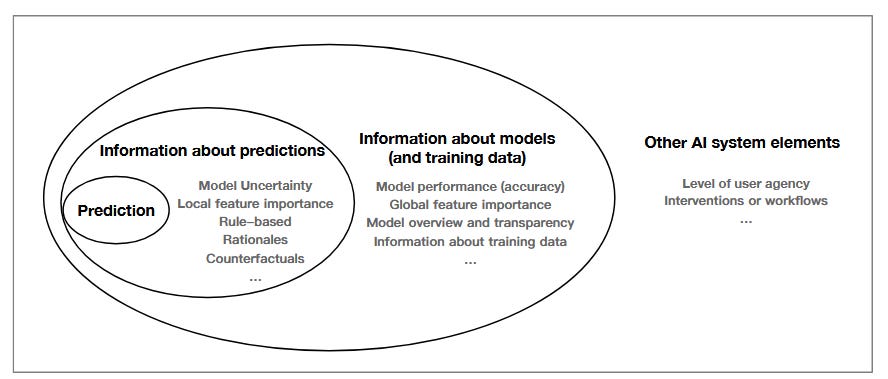
1. “Towards a Science of Human-AI Decision Making: A Survey of Empirical Studies” — Lai et al. (2021) | Preprint
A comprehensive survey of studies on AI-assisted decision making. Organizes AI assistance into four hierarchical categories: model predictions (core output), prediction-specific information (such as uncertainty and local explanations), global model insights (performance metrics and documentation), and system interaction elements (user agency and cognitive workflows).
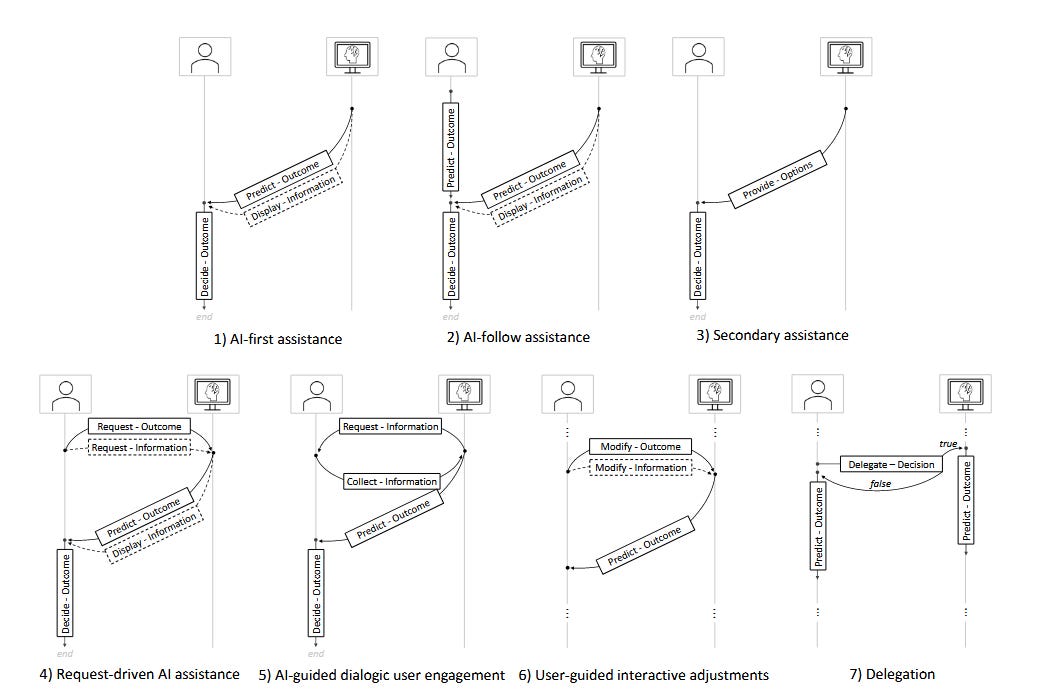
2. “Human-AI Collaboration is Not Very Collaborative Yet: A Taxonomy of Interaction Patterns” — Gomez et al. (2025) | Frontiers in Computer Science
A review that shows that current human-AI interactions are dominated by simplistic collaboration paradigms. Develops a taxonomy that identifies key interaction patterns, cautions that prevalent “static” paradigms like AI-first and AI-follow make users susceptible to anchoring and confirmation biases, while dynamic patterns like secondary, request-driven, dialogic, and user-guided assistance could help mitigate these.
3. “Human-in-the-Loop Machine Learning” (Book) — Robert Monarch (2021) | Manning Publications
Introduction to integrating human judgment into ML systems in specific ways. Less about human oversight, more about the role humans play in annotation, active learning, transfer learning, and using machine learning to optimize the process. Even though it’s a bit different from the other papers, it’s an interesting read on the role of humans in the machine ‘learning’ process. 📖 Manning Publications
Phase 2: The Blindspots
1. “Knowing About Knowing: An Illusion of Human Competence Can Hinder Appropriate Reliance on AI” — He et al. (2023) | ACM CHI 2023
Basically Dunning-Kruger with AI in the mix. And this was before we reached the capabilities of LLMs today. About how self-awareness affects how humans work with AI. Overconfident users tend to under-rely on superior AI systems. Intervention helps over-estimators calibrate their skills and improve reliance, but hurts under-estimators, who start to reject valid AI advice after realizing their own competence. Because of this, human oversight also depends on individual personalities. I wonder how this has changed with the state of LLMs today.
2. “Effect of Confidence and Explanation on Accuracy and Trust Calibration” — Zhang, Liao & Bellamy (2020) | ACM FACCT 2020*
Interesting study showing that confidence scores can help calibrate trust, but trust calibration alone is insufficient to improve AI-assisted decision making. Local explanations help even less with trust calibration and accuracy of AI-assisted decision making. Highlights that human and AI blind spots may be similar. I thought this was interesting as it showed that having explainability may not always help.
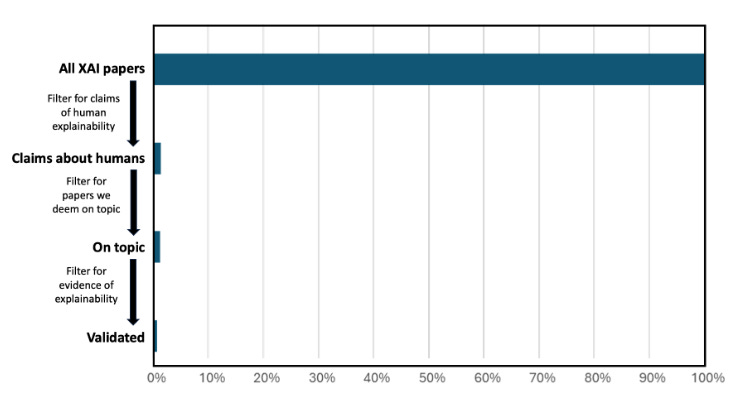
3. “Fewer Than 1% of Explainable AI Papers Validate Explainability with Humans” — Suh et al. (2025) | arXiv preprint
While this seems to belong better in a reading list on explainability, I thought it showed some key insights on the relationship between human oversight and explainability. The review shows that less than 1% of research papers on explainability validate their claims with human subjects. The authors argue that explainability methods that are not tested with humans are akin to releasing drugs based on biological principles without clinical trials.
Phase 3: Meaningful Oversight
1. “Designing Meaningful Human Oversight in AI” - Zhu et al. (2025) | SSRN Preprint
Focuses on why human oversight should go beyond just putting a “human-in-the-loop.” This paper argues AI should handle “operative agency” (generating solutions) while humans provide “evaluative agency” (understanding, verifying, intervening). Key principles: make verification easier than solving from scratch, focus on external reasoning aligned with expert judgment rather than explaining model internals, and ensure four conditions—clear boundaries with explicit handover points, full traceability, AI pursuing sub-goals while humans control top-level objectives, and AI adapting at micro-level while humans oversee major changes.
2. “Should I Follow AI-based Advice? Measuring Appropriate Reliance” — Schemmer et al. (2022) | arXiv preprint
Explains why current metrics are not appropriate for measuring the effectiveness of human oversight of AI. Proposes Relative Positive AI Reliance (human’s ability to switch to AI’s views when human was wrong and AI right), and Relative Positive Self-Reliance (human’s ability to stick to their own correct decision when AI provides incorrect advice).
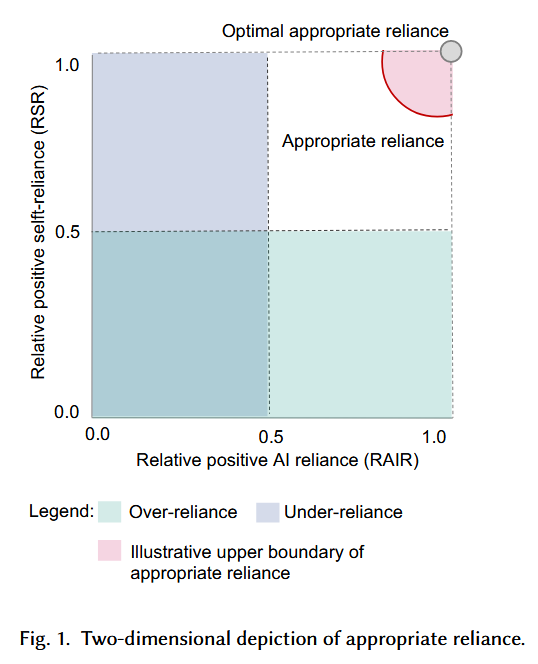
3. “Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance” — Bansal et al. (2021) | ACM CHI 2021
Even before Generative AI hallucinations became a common term, this study showed the tendency for humans to over-rely on explanations that AI provided for a prediction or recommendation, even when it was wrong. So, don’t always believe the reasoning from your friendly LLM. And it showed that a prediction or recommendation with a confidence score could lead to better performance by humans that were assisted by AI.
4. “Trust and Reliance in XAI — Distinguishing Between Attitudinal and Behavioral Measures” — Scharowski et al. (2022) | ACM CHI 2022 Workshop
Another interesting paper at the intersection of explainability and human oversight. It discusses the need to distinguish between trust in AI (which is an attitude) and reliance on AI (which is a behavior), and how papers have not clearly distinguished the two. And wonders whether ‘trust’ is even the right term to use when it comes to describing how humans interact with AI as it anthropomorphizes AI which has no agency nor an intent to betray us.
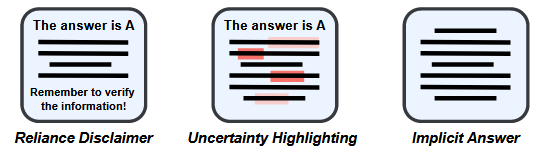
5. “To Rely or Not to Rely? Evaluating Interventions for Appropriate Reliance on Large Language Models” — Bo, Wan & Anderson (2024) | ACM CHI 2025
Interesting paper focusing on humans and LLMs. Examines interventions to help users calibrate their trust in LLMs. Looks at techniques like visually marking low-confidence words in red, or implicit answers i.e. providing reasoning steps but withholding the final result. While these techniques force user deduction and reduce over-reliance, they may fail to foster appropriate reliance as users may also under-rely on correct advice. The study highlights a paradox, where users become more confident when making incorrect reliance decisions. Also suggests that simple frictions, such as static disclaimers, may outperform complex technical interventions.
Phase 4: Agent Oversight
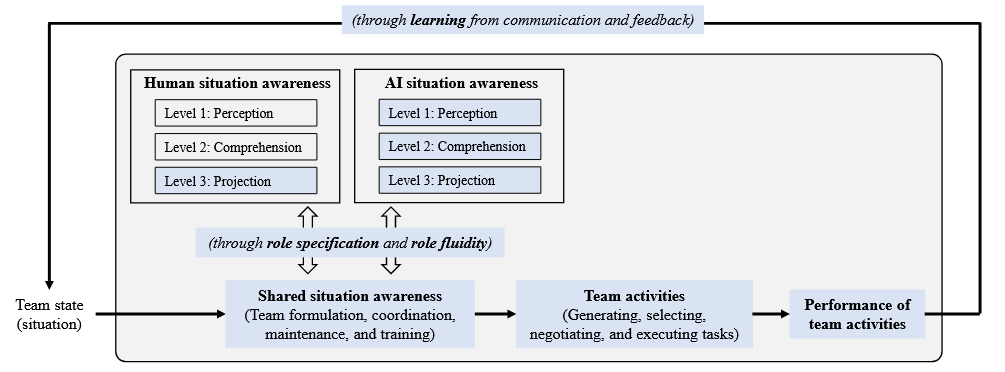
1. “Unraveling Human-AI Teaming: A Review and Outlook” — Lou et al. (2025) | arXiv preprint
An interesting look at how the shift to Agentic AI changes things fundamentally for human-AI interactions, as AI moves from being a passive tool to being able to plan, reflect. Raises an interesting point about AI potentially delegating to humans instead of the reverse. And how AI may change team dynamics, and how sycophancy of AI may cause a trust paradox due to its tendency to agree with humans even when wrong. The “peak-end” of human-AI interactions is also important to note as a single brilliant insight or a very smooth conclusion to a chat session can mask deeper reliability issues.
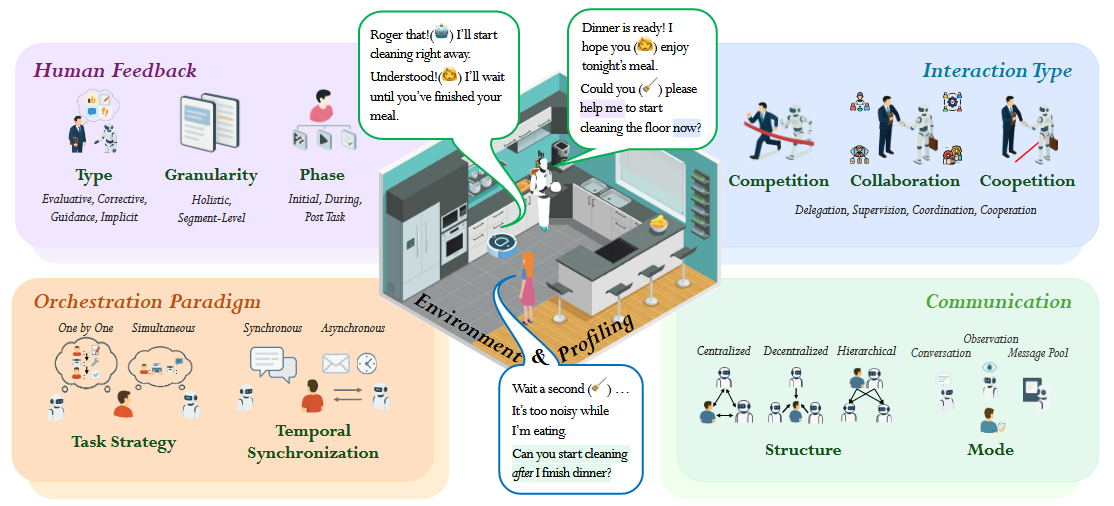
2. “LLM-Based Human-Agent Collaboration and Interaction Systems: A Survey” — Zou et al. (2025) | arXiv preprint
A survey of LLM-based human-agent systems. Looks at such systems through the lens of type, granularity and phase of human feedback; interactions that take the form of competition, collaboration and coopetition (both competitive and collaborative); orchestration paradigms based on task strategy that can be synchronous or asynchronous; as well as different forms of communication structures and modes.
So before just saying “We have a human-in-the-loop as a risk mitigant.”, think about this:
Humans are fallible - e.g., humans systematically over-rely on AI recommendations
Design matters - e.g., calibration matters as much as understanding the AI; explanations don’t automatically help human oversight, sometimes it hurts
It’s getting harder - e.g., autonomous agents make traditional oversight models increasingly inadequate
What resources would you add to this list?
#AIOversight #AIRiskManagement #AIReadingList